Projekt Informator
Projekt informator to REST’owy web service, działający w oparciu o Spring i Hibernate. Jeśli chcesz przeczytać więcej o projekcie i jego założeniach zapraszam do wprowadzenia.
Samouczek Programisty jest jednym z partnerów konferencji infoShare 2018.
infoShare 2018 to konferencja technologiczna odbywająca się 22-23 maja w Gdańsku. Na developerów czekają m.in. prelekcje z obszaru cybersecurity i machine learning, live coding oraz spotkania ze specjalistami, takimi jak: Filip Wolski, Trent McConaghy, Piotr Konieczny, Zbigniew Wojna czy Scott Helme. infoShare to także okazja do networkingu i udziału w imprezach towarzyszących. Sprawdź agendę i zarejestruj się na www.infoshare.pl.
![]()
Czym jest chmura
W uproszczeniu można powiedzieć, że chmura to środowisko, w którym uruchamia się aplikacje. Chmura to zestaw dużej liczby maszyn, które można “wynająć” na potrzeby swoich aplikacji.
W takim środowisku dostawca zapewnia mechanizmy administrowania maszynami i aplikacjami, które są na nich wdrażane (ang. deployed). We wszystkich znanych mi chmurach dostawca pobiera opłaty za wykorzystywane zasoby. To znaczy, że jeśli nasza aplikacja potrzebuje większej liczby maszyn/mocniejszych maszyn, wówczas dostaniemy większy rachunek do zapłacenia.
Dostawcy “rozwiązań chmurowych” oferują różne usługi. W przypadku Informatora używał będę wyłącznie podstawowych maszyn. Dodatkowo aplikacja korzystała będzie z bazy danych udostępnionej w chmurze.
Dostawca rozwiązań chmurowych
W przypadku Informatora, zależało mi wyłącznie na cenie. Chciałem, żeby do moich zastosowań chmura była darmowa :). Jednym z dostawców, który udostępnia maszyny za darmo1 jest Heroku.
Oczywiście istnieją też inni dostawcy. Najwięksi z nich to:
- Google Cloud Platform,
- Amazon Web Services2,
- Microsoft Azure Cloud Computing Platform.
Informator – stan projektu
Aplikacja używa najnowszych wersji biblioteki Spring MVC i Hibernate. W trakcie pisania tego artykułu najnowszymi wersjami były:
- Spring 5.0.4
- Hibernate 5.2.16
Aktualnie aplikacja to wyłącznie szkielet, który pozwala na pobranie encji z bazy danych i wyświetlenie jej w formacie JSON w odpowiedzi. Zachęcam do sprawdzenia źródeł projektu, pozwolą one zobaczyć przykładową konfigurację bez użycia Spring Boot.
Obecnie aplikacja zawiera jeden endpoint /speakers, który pozwala na pobranie informacji o prelegencie na podstawie identyfikatora. Aby aplikacja mogła pobrać dane z bazy muszą one być do niej wrzucone ręcznie. Na potrzeby testów utworzyłem kilka wierszy w tabeli uzupełniając je przykładowymi danymi:
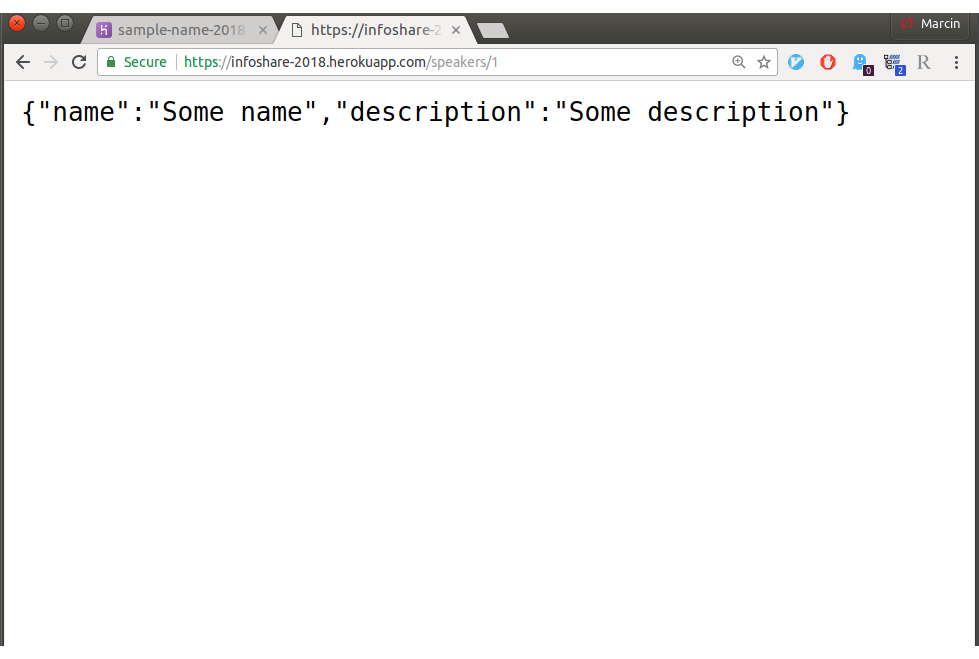
Heroku
Nigdy wcześniej nie wdrażałem aplikacji w Javie na Heroku i muszę powiedzieć, że dostawca ten przygotował bardzo dobrą dokumentację. Poniżej postaram się pokazać jak wygląda proces instalacji aplikacji krok po kroku.
Jak wspomniałem wcześniej, Informator to projekt “hobbystyczny”. W związku z tym, używam wyłącznie darmowe usługi Heroku. Na pewno nie sprawdziłyby się one w przypadku produkcyjnych aplikacji.
Wdrożenie aplikacji na Heroku
Cały proces należy zacząć od utworzenia konta na Heroku. Następnie można dodawać nowe aplikacje:
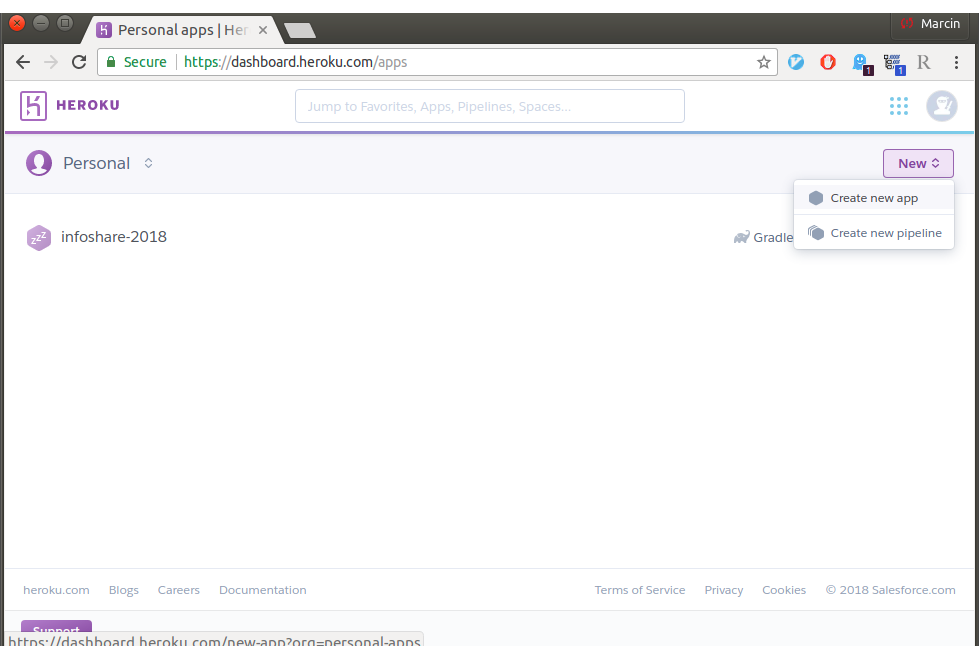
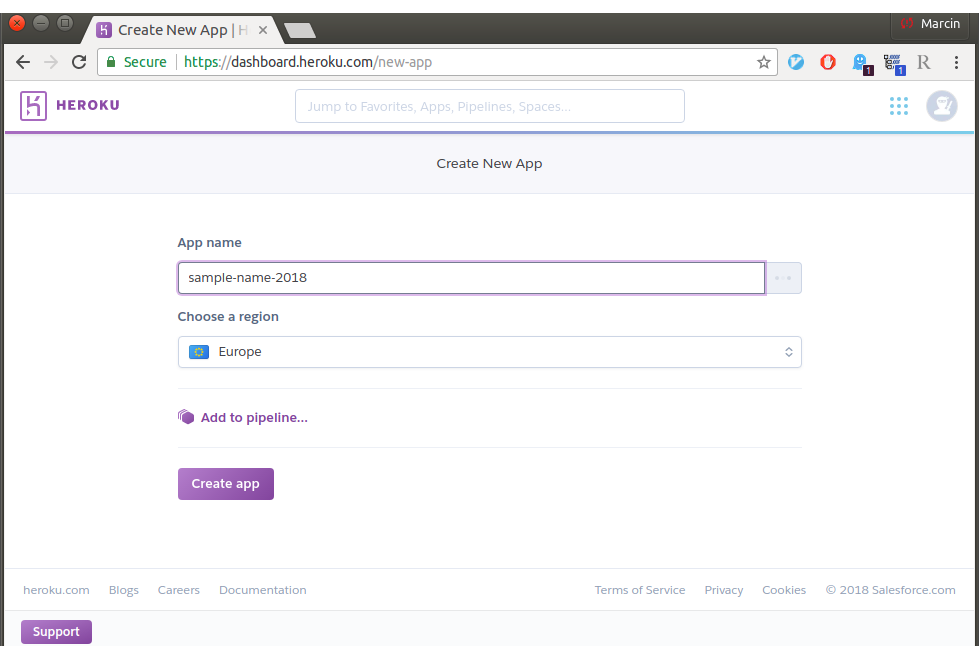
Następnie w zakładce Resources należy dodać komponent bazy danych. W przypadku Informatora jest to PostgreSQL.
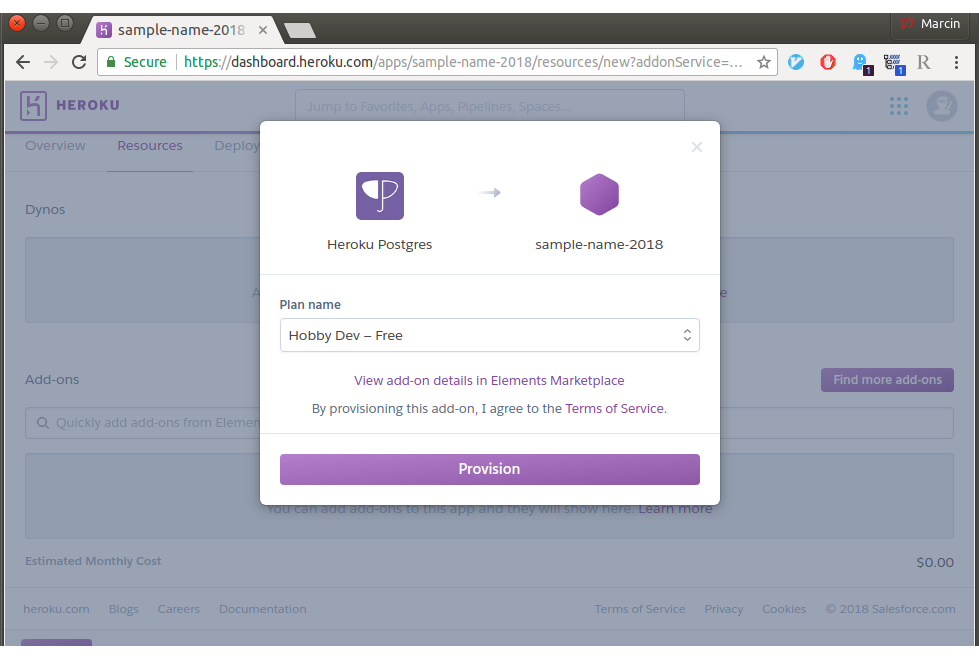
Zdecydowałem się na instalowanie aplikacji prosto z GitHub’a. Heroku domyślnie pozwala na taką integrację. Wymaga to zezwolenia na GitHub’ie do pobierania informacji o repozytoriach przez Heroku:
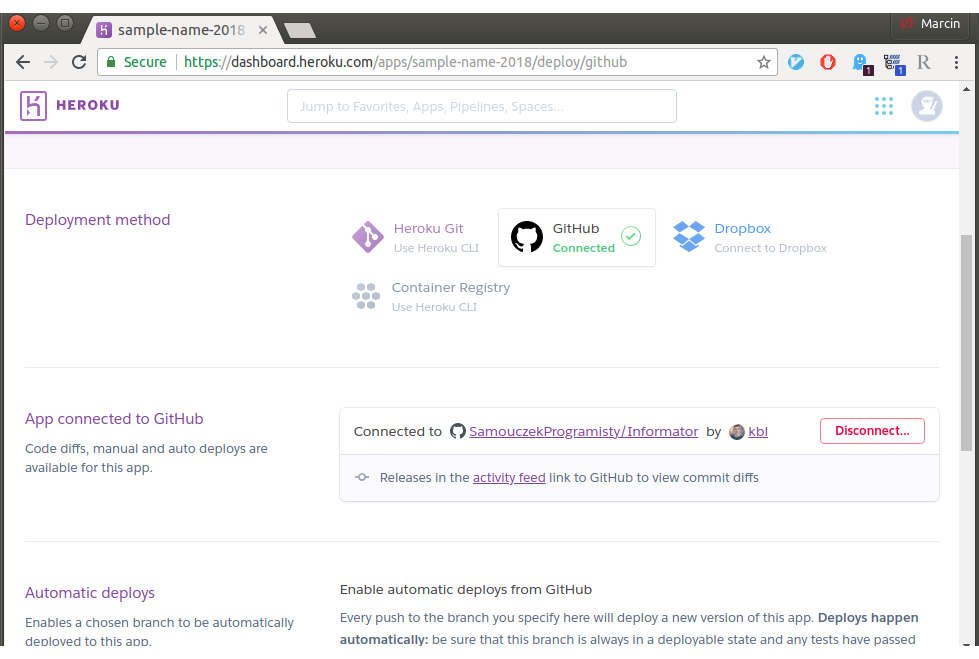
Sam proces instalacji aplikacji sprowadza się do naciśnięcia przycisku Deploy Branch. Wówczas Heroku pobiera aktualną wersję kodu i próbuje go uruchomić. Aby projekt mógł być uruchomiony na Heroku musi być odpowiednio przygotowany. O tym przygotowaniu przeczytasz w jednym z punktów poniżej:

Przygotowanie aplikacji do Heroku
Gradle
Do budowania Informatora używam Gradle. W przypadku tego projektu użyłem także webapp-runner. Dzięki tej bibliotece można uruchomić aplikację przy pomocy komendy java -jar webapp-runner.jar Informator.war. Właśnie ta komenda uruchamiana jest przez Heroku.
Heroku w trakcie instalowania aplikacji3 wywołuje zadanie stage. Definicja tego zadania w build.gradle wygląda następująco:
task stage() {
dependsOn clean, war
}
war.mustRunAfter clean
task copyToLib(type: Copy) {
into "$buildDir/server"
from(configurations.compile) {
include "webapp-runner*"
}
}
stage.dependsOn(copyToLib)
tasks.stage.doLast() {
delete fileTree(dir: "build/distributions")
delete fileTree(dir: "build/assetCompile")
delete fileTree(dir: "build/distributions")
delete fileTree(dir: "build/libs", exclude: "*.war")
}
Konfiguracja ta zapewnia, że plik webapp-runner.jar będzie znajdował się w katalogu build/server. Dodatkowo każde uruchomienie stage zapewni zbudowanie pliku war na nowo. Aby biblioteka webapp-runner była dostępna trzeba dodać ją do zależności:
dependencies {
compile 'com.github.jsimone:webapp-runner:8.5.29.0'
}
Plik Procfile
Procfile to plik konfiguracyjny wymagany przez Heroku. Wewnątrz tego pliku znajdują się komendy, które określają jak mają zachować się maszyny w trakcie instalowania aplikacji. Heroku działa w oparciu o tak zwane kontenery nazywane “dynosami”. Plik Procfile pokazuje komendy jakie mają być uruchomione na poszczególnych kontenerach.
Dla przykładu, kontener odpowiedzialny za serwer HTTP uruchamia następujące polecenie:
cd build ; java -jar server/webapp-runner-*.jar --expand-war --port $PORT libs/*.war
Polecenie to wywoływane jest po uruchomieniu zadania stage, które opisałem wcześniej. Dzięki tej kolejności na “dynosie” zbudowana jest aplikacja, którą można uruchomić przy użyciu wspomnianego wyżej webapp-runner’a.
Połączenie z bazą danych
Heroku dynamiczne tworzy bazy danych. Informacja gdzie dokładnie ta baza danych się znajduje przechowywana jest w zmiennej środowiskowej. Zmienna środowiskowa, która zawiera URL do bazy danych nazywa się JDBC_DATABASE_URL4. Zmienna ta powinna być użyta do utworzenia instancji DataSource:
@Bean
DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.postgresql.Driver");
dataSource.setUrl(System.getenv("JDBC_DATABASE_URL"));
return dataSource;
}
Podsumowanie
Aktualnie aplikacja to szkielet, na którym będę dobudowywał kolejne funkcjonalności. Główny etap konfiguracji jest już ukończony. Po przeczytaniu tego artykułu i przejrzeniu kodu źródłowego wiesz w jaki sposób zainstalować aplikację opartą o Spring MVC i Hibernate na Heroku. Jeśli nie robiłeś tego nigdy wcześniej zachęcam do samodzielnych prób, wtedy nauczysz się najwięcej.
Jeśli nie chcesz pominąć kolejnych artykułów na Samouczku proszę dopisz się do samouczkowego newslettera i polub Samouczka na Facebooku. Proszę podziel się linkiem do artykułu ze znajomymi, którym może on pomóc. Może to dzięki Tobie uda mi się dotrzeć do nowych czytelników? ;)
Do następnego razu!
-
Oczywiście są tu ograniczenia, firma też musi na czymś zarabiać ;). ↩
-
Tak właściwie to Heroku używa AWS do oferowania swoich usług. ↩
-
Dokładny sposób uruchamiania zależy m.in. od narzędzia użytego do budowania projektu. ↩
-
W zależności od sposobu łączenia się z bazą danych można użyć jednej z kilku zmiennych, na przykład
DATABASE_URLczySPRING_DATASOURCE_URL. ↩
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.




Zostaw komentarz