Czym jest protokół HTTP
Według słownika języka polskiego protokół to:
zasady wymiany informacji i współpracy programów i urządzeń komputerowych
Zatem protokół HTTP (ang. Hypertext Transfer Protocol) to zasady wymiany informacji i współpracy programów. Programami są serwery i klienty. Programy te wysyłają żądania (klienty) lub odpowiedzi (serwery). Przykładem klienta HTTP może być przeglądarka internetowa1. Klienty mogą interpretować uzyskane odpowiedzi, na przykład przeglądarka internetowa potrafi wyświetlić stronę internetową, która została przesłana przez serwer.
Nawiasem mówiąc przeglądarka robi całkiem sporo rzeczy w tle… Wiesz, że do wyświetlania strony www.amazon.com przeglądarka wykonuje około 300 żądań HTTP? W końcowej części artykułu pokażę Ci jak to się dzieje.
Komunikacja pomiędzy serwerem a klientem oparta jest na wielu innych protokołach. Ten zestaw protokołów nazywa się modelem ISO/OSI. Model ten zawiera warstwy. Każda warstwa, na bazie poprzednich, udostępnia dodatkowe funkcjonalności. Protokół HTTP znajduje się w najwyższej warstwie modelu, warstwie aplikacji.
Klienty wysyłają żądania. Każde żądanie powiązane jest z zasobem. Zasobem może być obrazek, strona HTML czy plik z kodem JavaScript. Sam protokół HTTP nie określa czym dokładnie jest zasób. Określa jedynie sposób w jaki można dostać się do zasobów. Każdy zasób ma swój unikalny identyfikator. Ten identyfikator to URI (ang. Uniform Resource Identifier).
Protokół HTTP dokładnie określa format komunikacji pomiędzy klientami i serwerami. Komunikacja ta oparta jest na wspomnianych już żądaniach i odpowiedziach. Protokół HTTP określa format tych wiadomości.
Protokół HTTP jest bezstanowy. Oznacza to tyle, że każde zapytanie może być interpretowane w oderwaniu od pozostałych.
Poza klientami i serwerami w komunikacji występują dodatkowe węzły. Na przykład mogą to być serwery, które zachowują kopię odpowiedzi przyspieszając komunikację. Mogą to być także elementy sieciowe pozwalające na sprawne dotarcie żądania do serwera. W tym artykule pominę te kwestie, moim zdaniem ich znajomość nie jest niezbędna do tworzenia aplikacji webowych.
Teraz wprowadzę Cię w poszczególne elementy składające się na protokół HTTP.
Adres czyli URL
Wspomniałem wcześniej o URI. Podzbiorem URI są URL (ang. Uniform Resource Locator). URI można traktować jako zbiór znaków który pozwala na unikalną identyfikację zasobu. URL natomiast poza tym unikalnym identyfikatorem zawiera informację dotyczącą “położenia” danego zasobu. Często określenia te stosowane są zamiennie.
Adres URL ma postać:
scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
Przykładowy adres URL może wyglądać następująco:
http://marcin:tajne@www.samouczekprogramisty.pl:80/nie/ma/tej?strony=1#identyfikator
| Część adresu | Przykładowa wartość |
|---|---|
scheme |
http |
user |
marcin |
password |
tajne |
host |
www.samouczekprogramisty.pl |
port |
80 |
/path |
/nie/ma/tej |
?query |
?strony=1 |
#fragment |
#identyfikator |
Zgodnie ze specyfikacją HTTP wielkość liter nie ma znaczenia w częściach scheme i host. Wielkość liter w pozostałych elementach ma znaczenie2.
Poniżej opiszę poszczególne części adresu URL.
scheme
W praktyce ta część adresu używana jest do określenia protokołu, najczęściej zobaczysz tu http czy https. W uproszczeniu można powiedzieć, że HTTPS (ang. Hypertext Transfer Protocol Secure) jest rozszerzeniem protokołu HTTP. To rozszerzenie pozwala na szyfrowanie połączenia pomiędzy klientem a serwerem.
user:password
user:password służą do uwierzytelniania. Uwierzytelnianie to proces, który polega na udowodnieniu, że klient wysyłający dane żądanie jest tym za kogo się podaje. Mechanizmu uwierzytelniania używasz praktycznie w każdym serwisie gdzie masz założone konto.
W tym przypadku nazwa użytkownika i hasło przesyłane są jako część URL. Nie jest to bezpieczne w przypadku używania protokołu HTTP. Nawet przy komunikacji protokołem HTTPS adres URL może być zapamiętany przez przeglądarkę. Daje to możliwość przechwycenia nazwy użytkownika i hasła. W związku z tym nie jest to bezpieczny sposób na przesyłanie hasła czy nazwy użytkownika i należy go unikać3.
host
W przypadku protokołu HTTP sprowadza się to do nazwy domeny internetowej lub adresu IP. Przykładem domeny może być www.samouczekprogramisty.pl. Przykładowy adres IPv4 to 192.30.253.112. Jaka strona kryje się pod tym adresem :)?
DNS (ang. Domain Name System) jest protokołem, który pozwala na tłumaczenie adresów IP na nazwy domen.
port
Port to numer. Numer ten jest wykorzystywany przez serwer. Serwer nasłuchuje ruch na danym porcie. To tak jak z numerem w bloku, domena to numer klatki a port to numer mieszkania ;).
Protokoły mają swoje standardowe porty. Na przykład standardowym portem protokołu HTTP jest 80. Protokół HTTPS natomiast używa portu 443. W praktyce, ze względu na domyślne wartości, porty te często się pomija. Odpowiednia wartość pola scheme pozwala na określenie czy użytkownikowi chodzi o port 80 czy 443.
Możesz także uruchomić serwer, który nasłuchuje na innym porcie. Przykładem może tu być Tomcat, który domyślnie uruchamia się na porcie 8080. W takim przypadku podanie portu jest konieczne.
path
Ta część adresu URL jest ścieżką, która określa zasób. Na przykład w adresie www.samouczekprogramisty.pl/kurs-programowania-java ścieżką jest /kurs-programowania-java.
query
Zawiera dodatkowe dane identyfikujące dany zasób. Ta część oddzielona jest od ścieżki znakiem ?. W praktyce zawiera pary klucz=wartość połączone znakiem &. Na przykład:
?parametr=wartosc&format=json
fragment
Ostatnia część adresu URL. W praktyce wykorzystywana jest do określenia fragmentu strony HTML, która powinna zostać pokazana użytkownikowi. Na przykład adres https://www.samouczekprogramisty.pl/strumienie-w-jezyku-java/#właściwości-strumieni przeniesie Cię do sekcji opisującej właściwości strumieni.
Pisząc bardziej formalnie fragment używany jest do określenia „podzbioru” zasobu (ang. secondary resource). W przypadku HTML zasobem jest strona HTML a podzbiorem sekcja tej strony. Zgodnie ze specyfikacją ta część adresu URL służy do identyfikacji zasobu wyłącznie po stronie klienta. Oznacza to tyle, serwer do identyfikacji zasobu nie używa tej części URL.
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.
Żądanie i odpowiedź
W dalszej części artykułu będę używał programu curl jako klienta HTTP. Jest to program, który pozwala na łatwe wysyłanie zapytań do serwerów z linii poleceń.
Jeśli nie chcesz używać tego programu możesz użyć narzędzi dla programistów dostępnych w Twojej przeglądarce:
Teraz przeanalizuję przykładowe zapytanie wraz z odesłaną odpowiedzią. Użyję do tego publicznego API Github’a. Github używa HTTPS, w analizie żądania/odpowiedzi pominę fragmenty dotyczące HTTPS.
Żądanie HTTP
Klient wysyła żądanie do serwera w formie wiadomości. Wiadomość ta ma dokładnie zdefiniowany format:
- linia określająca czasownik HTTP, zasób i wersję protokołu,
- linie zawierające nagłówki,
- pustą linię określającą koniec nagłówków,
- ciało wiadomości (jeśli istnieje).
Jak wspomniałem wyżej użyję programu curl. Dodatkowo użyję przełącznika -v. Włącza on tryb lania wody ;). Wtedy curl raportuje dużo więcej informacji. Dane wysłane do serwera poprzedzone są znakiem >. Odpowiedź poprzedzona jest <. Poniżej pokazuję zapytanie do API Githuba. Wysyłam żądanie na adres https://api.github.com/users/kbl:
$ curl -v https://api.github.com/users/kbl
// ciach usunąłem część związaną z HTTPS
> GET /users/kbl HTTP/1.1
> Host: api.github.com
> User-Agent: curl/7.52.1
> Accept: */*
>
Zacznę od analizowania pierwszej linijki GET /users/kbl HTTP/1.1. Na początku zawiera ona czasownik HTTP - GET (czasowniki opiszę dokładniej poniżej). Następnie zawiera część adresu URL, wszystko od części path. W moim przypadku jest to /users/kbl. Kolejną częścią jest protokół wraz z wersją HTTP/1.1.
Trzy kolejne linijki zawierają tak zwane nagłówki HTTP, nagłówkom także poświęcę osobny podpunkt poniżej.
W przypadku tego żądania, ciało wiadomości jest puste. Widzisz więc tylko pustą linię oddzielającą nagłówki od pominiętego ciała wiadomości.
Odpowiedź HTTP
Serwer odpowiada na żądanie klienta wysyłając odpowiedź4. Podobnie jak w przypadku zapytania format jest dokładnie określony:
- linijka z wersją protokołu i statusem odpowiedzi,
- linie zawierające nagłówki,
- pustą linię określającą koniec nagłówków,
- ciało wiadomości (jeśli istnieje).
Tym razem odpowiedź, jest dużo dłuższa:
< HTTP/1.1 200 OK
< Server: GitHub.com
< Date: Tue, 06 Feb 2018 19:36:28 GMT
< Content-Type: application/json; charset=utf-8
< Content-Length: 1218
< Status: 200 OK
< X-RateLimit-Limit: 60
< X-RateLimit-Remaining: 55
< X-RateLimit-Reset: 1517949218
< Cache-Control: public, max-age=60, s-maxage=60
< Vary: Accept
< ETag: "268c03d98e6e20c7824364d61b3f51b0"
< Last-Modified: Mon, 09 Oct 2017 19:42:33 GMT
< X-GitHub-Media-Type: github.v3; format=json
< Access-Control-Expose-Headers: ETag, Link, Retry-After, X-GitHub-OTP, X-RateLimit-Limit, X-RateLimit-Remaining, X-RateLimit-Reset, X-OAuth-Scopes, X-Accepted-OAuth-Scopes, X-Poll-Interval
< Access-Control-Allow-Origin: *
< Content-Security-Policy: default-src 'none'
< Strict-Transport-Security: max-age=31536000; includeSubdomains; preload
< X-Content-Type-Options: nosniff
< X-Frame-Options: deny
< X-XSS-Protection: 1; mode=block
< X-Runtime-rack: 0.030276
< X-GitHub-Request-Id: 8AAA:602C:92D77:140069:5A7A03BC
<
{
"login": "kbl",
// ciach
"created_at": "2009-04-14T08:28:56Z",
"updated_at": "2017-10-09T19:42:33Z"
}
Pierwsza linijka to wspomniany wcześniej protokół HTTP/1.1. Następnie status odpowiedzi 200 OK, podobnie jak w przypadku nagłówków i czasowników więcej o statusie przeczytasz w osobnym podpunkcie.
Kolejne 22 linijki to nagłówki, po których występuje pusta linia. Podobnie jak przy żądaniu oddziela ona nagłówki od ciała wiadomości.
W przypadku odpowiedzi ciało wiadomości zawiera dane w formacie JSON – zasób. Dla czytelności pominąłem tu większość ciała odpowiedzi. Zachęcam Cię do eksperymentowania z własnymi zapytaniami :). Do tych eksperymentów może Ci się przydać dokumentacja API.
Czasowniki HTTP
Specyfikacja HTTP definiuje 8 czasowników5. Każdy z tych czasowników powiązany jest z żądaniem wysyłanym przez klienta. Każde z żądań ma swoje zastosowania.
Zanim przejdę do omówienia poszczególnych czasowników musisz wiedzieć czym jest cache6. Cache to mechanizm, który pozwala na zmniejszenie czasu oczekiwania na odpowiedź. Zakładając, że wykonasz dwa zapytania z rzędu o ten sam zasób wynik pierwszego zapytania może być zapisany w cache’u. W związku z tym drugie zapytanie może nie dotrzeć do serwera, odpowiedź może zostać pobrana z cache’a.
GET
Jest to podstawowe żądanie. Każde otworzenie strony internetowej zaczyna się od zapytania typu GET. Przeglądarka wysyła żądanie typu GET żeby otworzyć stronę internetową. Specyfikacja mówi, że żądanie to służy do pobrania aktualnej reprezentacji zasobu. W praktyce może to oznaczać pobranie aktualnej wersji strony znajdującej się pod danym adresem. Zakłada się, że żądania typu GET nie posiadają dołączonego ciała wiadomości.
Odpowiedź na żądania typu GET może być przechowywana w cache’u.
HEAD
Zapytanie typu HEAD jest podobne do GET. Różni się jednym ważnym szczegółem. W przypadku tego zapytania odpowiedź serwera nie może zawierać ciała wiadomości. Zapytania tego typu są używane do sprawdzenia czy dany zasób się zmienił, czy do sprawdzania poprawności odnośników. Zysk z używania tego zapytania polega na tym, że ciało wiadomości nie jest przesyłane. Wyobraź sobie plik PDF, który zawiera 10MB danych. Można wysłać zapytanie typu HEAD, żeby sprawdzić czy zawartość tego pliku uległa zmianie. To czy plik jest nowszy można określić na podstawie nagłówków, które będą dołączone do odpowiedzi.
Odpowiedź na żądania typu HEAD może być przechowywana w cache’u.
POST
Specyfikacja mówi, że żądania typu POST są przetwarzane przez serwer zgodnie z założeniami dla danego zasobu. Taki skomplikowany opis sprowadza się do:
- używania
POSTdo przesyłania zawartości formularzy, - dodawania nowego zasobu,
- dodawanie danych do istniejącego zasobu.
Odpowiedzi na żądania typu POST nie są przechowywane w cache’u7.
PUT
W codziennym użytkowaniu żądania typu PUT służą do aktualizacji danego zasobu. Zgodnie ze specyfikacją ciało wiadomości powinno posłużyć do ustawienia stanu zasobu na serwerze. Zatem w przypadku gdy zasób nie istniał żądanie tego typu powinno go utworzyć. Jeśli zasób istnieje wówczas jego stan powinien być ustawiony na ten przekazany w ciele wiadomości.
W większości znanych mi przypadków ten pierwszy aspekt jest pomijany, prawdopodobnie dla uproszczenia logiki aplikacji.
Główna różnica pomiędzy zapytaniami POST i PUT polega na sposobie interpretowania ciała wiadomości. W przypadku zapytania typu POST to zasób decyduje jak przetworzyć otrzymaną wiadomość. W przypadku żądania typu PUT otrzymana wiadomość powinna posłużyć do ustawienia wartość zasobu.
Odpowiedzi na żądanie typu PUT nie powinny być przechowywane w cache’u.
Idempotentność
Oznacza to tyle, że zapytania typu PUT są idempotentne. Zapytania, które są idempotentne można powtarzać wielokrotnie i zawsze doprowadzą one do tego samego stanu danego zasobu.
DELETE
Zapytania tego typu służą do usuwania zasobów. Na przykład w którymś z wcześniejszych zapytań dany zasób może być utworzony przy pomocy żądania typu POST. Następnie może on być usunięty przy pomocy DELETE. Odpowiedzi na żądania tego typu nie powinny zawierać ciała wiadomości.
Odpowiedzi na żądania typu DELETE nie powinny być umieszczane w cache’u.
CONNECT
Żądania tego typu służą do utworzenia połączenia pomiędzy klientem a serwerem docelowym (za pomocą węzłów pośrednich). W praktyce nie będziesz używał tego typu żądań w trakcie pisania aplikacji webowych. Mi się to nigdy do tej pory nie zdarzyło :).
OPTIONS
Żądania typu OPTIONS używane są do pobrania informacji na temat możliwości komunikacji dla danego zasobu. W praktyce żądania tego typu używane są do sprawdzenia jakie żądania są obsługiwane przez serwer. Żądanie tego typu także wykorzystywane jest w mechanizmie CORS.
Odpowiedzi na żądania typu OPTIONS nie powinny być przechowywane w cache’u.
TRACE
Żądanie tego typu służy do testowania. W odpowiedzi na to żądanie serwer powinien wysłać zapytanie, które otrzymał. Możliwa jest drobna modyfikacja otrzymanych nagłówków, na przykład serwer może usunąć nagłówki zawierające dane wrażliwe (na przykład ciasteczka). Żądanie typu TRACE nie może zawierać ciała wiadomości.
Odpowiedzi na żądanie typu TRACE nie powinny być umieszczane w cache’u.
Nagłówki HTTP
Nagłówki dołączane są przez klienty do wysyłanych zapytań i przez serwery do wysyłanych odpowiedzi. Mają one postać nazwa-nagłówka: wartość-nagłówka. Zgodnie ze specyfikacją wielkość liter w nazwach nagłówków nie ma znaczenia. Wielkość liter w wartości nagłówka może mieć znaczenie, zależy to od aplikacji. Chociaż istnieje cała masa standardowych nagłówków możesz tworzyć swoje własne.
Nagłówki wykorzystywane są do przesyłania metadanych na temat zasobów. Mogą zawierać na przykład informacje o formacie, statusie odpowiedzi czy dacie. Poniżej postaram się wyjaśnić kilka najczęściej spotykanych nagłówków:
| Nagłówek | Znaczenie |
|---|---|
Accept |
Klient informuje serwer o tym jaki format jest w stanie zrozumieć, może to być na przykład JSON: application/json |
Accept-Encoding |
Klient informuje serwer o tym jakie sposoby kodowania ciała wiadomości rozumie, może być użyty do określenia pożądanego algorytmu kompresji odpowiedzi |
Access-Control-Allow-Methods |
W odpowiedzi na zapytanie typu OPTIONS serwer informuje jakie inne czasowniki HTTP są dozwolone |
Access-Control-Allow-Origin |
Serwer informuje klienta jakie domeny uprawnione są do użycia odpowiedzi |
Cache-Control |
Nagłówek służący do zarządzania cache’owaniem. Dotyczy zarówno żądań jak i odpowiedzi |
Connection |
Zawiera informacje na temat połączenia pomiędzy klientem a serwerem |
Content-Encoding |
Serwer informuje klienta o sposobie kodowania ciała wiadomości |
Content-Type |
Odpowiednik nagłówka Accept wysyłany przez serwer informujący o formacie odpowiedzi |
Cookie |
Nagłówek służący do przesłania ciasteczka przez klienty do serwera |
Date |
Zawiera datę mówiącą o czasie wygenerowania żądania/odwiedzi |
ETag |
Zawiera identyfikator zasobu zwróconego przez serwer. Używany przez cache |
Host |
Zawiera domenę, do której wysyłane jest żądanie |
Location |
Zawiera informacje o położeniu zasobu, może być użyty na przykład przy przekierowaniach i tworzeniu nowych zasobów |
Server |
Serwer informuje klienty jakiego oprogramowania używa do obsługi odpowiedzi |
Set-Cookie |
Nagłówek służący do ustawienia ciasteczka |
User-Agent |
Nagłówek dołączany do zapytania informujący o tym jaki klient został użyty do jego wysłania |
Ciasteczka
Co prawda ciasteczka to nic innego jak nagłówki, jednak poświęcę im osobny podpunkt. W osobnym artykule możesz przeczytać o ciasteczkach w kontekście specyfikacji serwletów.
Wiesz już, że protokół HTTP jest bezstanowy. Serwer HTTP nie może powiązać ze sobą zapytań pochodzących od tego samego klienta w jedną paczkę. Z pomocą przychodzą ciasteczka. Ciasteczka to specyficzne nagłówki, które są obsługiwane przez klienty.
Serwer w odpowiedzi może wysłać nagłówek, który utworzy ciasteczko. Ciasteczko to jest przypisane do domeny (część host i path adresu URL). Przykładowy nagłówek do ustawienia ciasteczka może wyglądać następująco:
Set-Cookie: <nazwa ciasteczka>=<wartość ciasteczka>
W każdym kolejnym zapytaniu do tej domeny klient dołącza nagłówki ciasteczek. Dzięki temu aplikacja na serwerze może połączyć pojedyncze zapytania w sesje. Przykładowe ciasteczko w odpowiedzi dołączane jest przy pomocy nagłówka:
Cookie: <nazwa ciasteczka>=<wartość ciasteczka>
Pewnie kojarzysz formularze logowania, w których możesz zaznaczyć “zapamiętaj mnie”. Zaznaczenie tego pola powoduje wysłanie odpowiedzi przez serwer, w której znajduje się nagłówek z ciasteczkiem (nagłówek Set-Cookie). To ciasteczko zawiera unikalny klucz, który później jest dołączany przez klienta do każdego żądania do danej domeny (nagłówek Cookie). Dzięki temu każde kolejne zapytanie ma nagłówek z tym tokenem. Aplikacja na serwerze widząc ten token może potwierdzić tożsamość użytkownika.
Niestety ciasteczka wykorzystywane są także do złych celów. Ciasteczka mogą być wykorzystywane jako jeden ze sposobów do śledzenia Twojego ruchu w sieci. Zdarzyło Ci się kliknąć na reklamę a później ta reklama pokazywała Ci się bez przerwy? Ciasteczka także mogły się do tego przyczynić8.
Statusy HTTP
Wiesz już, że każda odpowiedź od serwera zawiera między innymi informacje o statusie. Status ten jest podstawową informacją o tym czy żądanie się powiodło. Wszystkie statusy podzielone są na pięć grup.
Statusy 1xx
Szczerze nigdy w praktyce nie spotkałem się z użyciem tych statusów. Ta grupa statusów to statusy informacyjne. Informują klienty o tym, że zapytanie zostało otrzymane i jest przetwarzane.
Statusy 2xx
Statusy z tej grupy informują o tym, że zapytanie zostało poprawnie przetworzone. W zależności od kodu odpowiedzi wynik tego przetwarzania może być różny. Najczęściej używane statusy z tej grupy to:
200 OK– zapytanie zostało przetworzone poprawnie,201 Created– zapytanie zostało przetworzone poprawnie i zasób został utworzony,202 Accepted– zapytanie zostało przyjęte przez serwer, jednak jego przetwarzanie nie jest jeszcze ukończone,204 No Content– zapytanie zostało przetworzone, ciało wiadomości jest puste.
Statusy 3xx
Statusy zaczynające się od 3 informują klienty o tym, że musi być podjęta dodatkowa akcja w celu skończenia przetwarzania zapytania. Statusy te wykorzystywane są do ustawiania przekierowań. Na przykład jeśli zmieniłbym adres samouczka z www.samouczekprogramisty.pl na cokolwiek innego wówczas żądanie wysłane pod www.samouczekprogramisty.pl powinno skończyć się statusem z grupy 3xx:
301 Moved Permanently– informuje klienta, że zasób został przeniesiony na stałe w inne miejsce. Ten status ma znaczenie duże dla twórców stron, którzy bazują na ruchu z wyszukiwarek. Taki status informuje wyszukiwarki o tym, że strona, która wcześniej była pod adresem X znajduje się w nowym miejscu.
Statusy 4xx
Statusy z tej grupy informują o błędzie klienta. Pewnie nie raz widziałeś błąd 404 ;). Serwer tymi statusami informuje o tym, że żądanie nie może być poprawnie przetworzone:
400 Bad Request– serwer informuje klienta o błędnym zapytaniu, które nie będzie przetworzone,403 Forbidden– zasób wymaga uwierzytelnienia, po potwierdzeniu tożsamości może być dostępny,404 Not Found– to pewnie znasz i widziałeś wielokrotnie, żądany zasób nie istnieje.
Statusy 5xx
Tutaj sprawa jest poważna. Serwer informuje klienty o błędzie po stronie serwera, które uniemożliwiają przetworzenie zapytania:
500 Internal Server Error– informacja dla klienta o tym, że serwer znalazł się w stanie, który uniemożliwia poprawne przetworzenie żądania,502 Bad Gateway– na początku artykułu wspomniałem o tym, że może być wiele węzłów, które będą przekazywały zapytanie do serwera, który je finalnie obsłuży. Ten status informuje klienta o tym, że jeden z tych pośrednich węzłów dostał błędną odpowiedź od poprzedniego węzła,503 Service Unavailable– ten błąd może informować klienta o tym, że serwer jest przeciążony. Ponowna próba może kończyć się poprawną odpowiedzią.
Prawie 300 zapytań aby wyświetlić stronę
Teraz jak już wiesz czym jest protokół HTTP wyjaśnię “tajemnicę” około 300 zapytań.
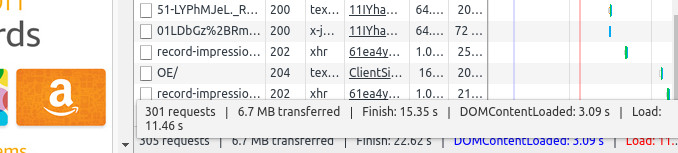
Przeglądarka jest klientem HTTP. Klienty mogą interpretować odpowiedź wysyłaną od serwera. Wpisując w pasek adresu www.amazon.com i naciskając ENTER wysyłasz jedno zapytanie. Jest to zapytanie typu GET o zasób www.amazon.com. W odpowiedzi serwer zwraca dokument HTML.
Dokument ten jest interpretowany przez przeglądarkę, zawiera on znaczniki HTML. Takie jak img, script czy style. Każdy z tych znaczników może kończyć się kolejnym zapytaniem typu GET. Dodatkowo kod JavaScript interpretowany przez przeglądarkę może wykonywać dodatkowe zapytania. W sumie do wyświetlenia strony głównej sklepu Amazon potrzeba tych zapytań około 300. A wszystko zaczęło się od jednego, niewinnego GET :).
Dodatkowe materiały
Odsyłam Cię głównie do źródeł. Mam wrażenie, że artykuł jest na tyle szczegółowy, że bardziej dokładne informacje znajdziesz właśnie tam:
- Zbiór materiałów fundacji Mozilla dotyczących HTTP,
- Zbiór RFC dla HTTP 1.1:
- RFC dla URI
Podsumowanie
Jeśli przeczytałeś i zrozumiałeś ten artykuł to śmiało możesz powiedzieć, że znasz protokół HTTP. Wiesz jak działa ten protokół, wiesz czym są zasoby. Poznałeś różnicę pomiędzy URI a URL. Znasz mechanizm działania nagłówków, poznałeś też główne statusy odpowiedzi. Moim zdaniem, poznając to wszystko wyszedłeś poza podstawową wiedzę na temat tego protokołu.
Zapowiadało się niewinnie a wyszedł tasiemiec. Sporo napracowałem się przy tym artykule, więc będę Ci bardzo wdzięczny za udostępnienie go dalej :).
Jeśli nie chcesz pominąć kolejnych artykułów na Samouczku proszę dopisz się do samouczkowego newslettera i polub Samouczka na Facebooku. Trzymaj się! :)
-
Ot, taki “patriotyzm lokalny” – aktualnie pracuję w firmie Opera Software ;). ↩
-
To czy wielkość liter jest rozróżniana zależy od aplikacji obsługującej dane żądanie. ↩
-
Potrafię sobie wyobrazić wyjątki od tej reguły. Na przykład w komunikacji, w której adres URL jest przesyłany zaszyfrowanym kanałem. ↩
-
Na jedno żądanie serwer może wysłać kilka odpowiedzi, na przykład dzieląc dużą odpowiedź na kilka mniejszych. ↩
-
Tutaj podobnie jak z webservice’em postanowiłem nie tłumaczyć tego określenia. Jest ono na tyle powszechne, że nawet nie wiem jakie byłoby dobre tłumaczenie. Schowek? Skrytka? ;) ↩
-
W większości przypadków, specyfikacja dopuszcza wyjątki od tej reguły. ↩
-
Ciasteczka nie są jedynym narzędziem używanym do śledzenia użytkownika. Podobnie sprawa wygląda z reklamami, to nie tylko ciasteczka mogą służyć do wybierania tych do wyświetlenia dla Ciebie. ↩
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.




Zostaw komentarz