Artykuł ten opisuje przykładową implementację struktury danych określanej jako tablica asocjacyjna. Tę strukturę nazywa się też słownikiem czy mapą. Sama struktura występuje w wielu językach programowania. Zasada działania tej struktury jest niezależnie od języka programowania.
Przykładową implementację przygotowałem w Javie. Aby wynieść jak najwięcej z tego artykułu powinieneś wiedzieć czym są metody hashCode i equals. Powinieneś też znać kontrakt pomiędzy metodami equals i hashCode.
Do zrozumienia przykładowej implementacji niezbędna będzie też wiedza o typach generycznych.
Może przydać się też wiedza na temat szacowania złożoności obliczeniowej.
Czym jest tablica asocjacyjna
Tablica asocjacyjna to struktura, która pozwala na przechowywanie par. Każda para zawiera klucz i wartość. Dzięki kluczowi jesteś w stanie w prosty sposób znaleźć wartość skojarzoną z danym kluczem. Klucz jest unikalny w ramach całej tablicy asocjacyjnej.
Przykładem tablicy asocjacyjnej może być zwykły słownik wyrazów obcych. Na przykład słownik polsko-angielski. Kluczami w tym przypadku są słowa po polsku, wartościami ich angielskie odpowiedniki.
Istnieje wiele możliwych sposobów na zaimplementowanie tej struktury danych. Jednym z nich jest tablica asocjacyjna oparta o funkcję skrótu. Założeniem tej implementacji jest uzyskanie bardzo dobrych czasów dostępu do danych. Dodawanie nowych elementów do mapy także powinno być szybkie.
Czym jest funkcja skrótu
Funkcja skrótu to funkcja, która z wartości może wyprodukować klucz. Klucz ten jest zawsze ten sam dla danej wartości. Przykładem funkcji skrótu w języku Java jest funkcja hashCode.
Funkcja ta zazwyczaj zwraca liczbę typu int. Jest ona bardzo ważna dla wydajnego działania tej implementacji mapy. Powinna ona zwracać wartości, które są dobrze rozdystrybuowane. Innymi słowy, funkcja skrótu, która zawsze zwraca wartość 1 nie jest najlepszym pomysłem. Zwracane wartości powinny być równomiernie rozrzucone po wszystkich liczbach. W dalszej części artykułu przeczytasz o tym dlaczego jest to ważne.
Wspomniałem już wyżej, że tablicę asocjacyjną nazywa się także słownikiem czy mapą. Od teraz będę posługiwał się określeniem mapa. Dalsza część artykułu opisuje implementację mapy opartą o funkcję skrótu.
Jak działa HashMap
Fragmenty kodu, które prezentuję poniżej pochodzą z uproszczonej implementacji mapy. Nie zmieniają one zasady działania tej implementacji. Te uproszczenia mają pomóc Ci zrozumieć sposób działania tej struktury danych.
Mapa to zestaw par, par kluczy i wartości. Do reprezentacji takiej pary potrzebna jest osobna klasa. Może ona wyglądać następująco:
private static class Entry<K, V> {
private final K key;
private V value;
Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
Sama klasa mapy powinna przechowywać te pary. Dobrym sposobem może być użycie tablicy:
public class SimpleHashMap<K, V> {
private Entry<K, V>[] table;
}
Tylko jak duża powinna być ta tablica? Ile elementów chcemy przechowywać w mapie? Uniwersalna implementacja nie może tego założyć. Zakłada więc rozsądne wartości domyślne:
public class SimpleHashMap<K, V> {
private static final int INITIAL_CAPACITY = 4;
private Entry<K, V>[] table;
public SimpleHashMap() {
table = new Entry[INITIAL_CAPACITY];
}
}
Co jeśli chcemy wrzucić do mapy więcej niż 4 wartości? Implementacja ta zakłada, że tablica ta zostanie rozszerzona. Jak? Opiszę to niżej. Teraz proszę skup się na zmiennej table.
Zmienna table przechowuje instancje klasy Entry<K, V>, czyli pary klucz-wartość. Aby ta struktura pozwalała na szybkie wstawianie/dostęp do elementów musi być prosty sposób na zmapowanie klucza na indeks w tej tablicy. Dochodzimy tu do zastosowania funkcji skrótu.
Zastosowanie funkcji skrótu
Funkcja skrótu pozwala na zmapowanie klucza na indeks w tablicy wspomnianej wyżej. Wartość zwrócona przez metodę hashCode (funkcję skrótu) musi zostać dopasowana do wielkości tablicy. Najprostszym sposobem jest użycie reszty z dzielenia:
private int hash(K key) {
if (key == null) {
return 0;
}
return Math.abs(key.hashCode() % table.length);
}
Zakładając, że nasza tablica ma wielkość 4 mapowanie wartości hashCode na indeks tablicy wygląda następująco:
Wartość hashCode |
Indeks w tablicy |
|---|---|
| 1 | 1 |
| 3 | 3 |
| 6 | 2 |
| -4 | 0 |
| -5 | 1 |
| 17 | 1 |
Funkcja skrótu dzieli cały możliwy zakres liczb na przedziały. Przedziały te nazywa się wiadrami (ang. bucket). Dzięki temu, aby znaleźć interesujący nas element na podstawie klucza, musimy przejrzeć tylko jeden przedział.
Podział na przedziały ma istotny wpływ na wydajność pracy na mapie.
Powtarzające się indeksy
A co jeśli pod danym indeksem występuje już element? Co jeśli dodamy dwa różne klucze, których funkcja hashCode zwróci tę samą wartość? Jeśli klucze są równe (czyli equals potwierdza, że obiekty są sobie równe) wtedy należy nadpisać wartość. Jeśli jednak hashCode jest ten sam a equals mówi, że obiekty są różne mamy problem ;).
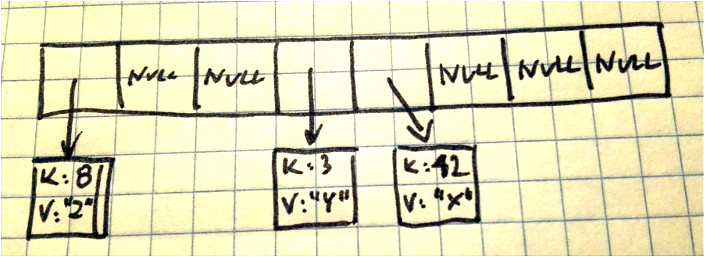
Z tego właśnie powodu w tablicy nie trzymamy par. Trzymamy kolekcję par:
public class SimpleHashMap<K, V> {
private static final int INITIAL_CAPACITY = 4;
private List<Entry<K, V>>[] table;
}
Dlatego właśnie zmienna table jest tablicą list wiązanych zawierających pary elementów.
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.
Lepsza wydajność dostępu do danych
Jednak nawet takie zachowanie nie rozwiązuje problemu. Pamiętasz domyślną wielkość tablicy? W przykładzie powyżej było to 4. Oznacza to tyle, że wszystkie możliwe wartości hashCode podzielone są na 4 przedziały. Jeśli w naszej mapie będzie odpowiednio dużo elementów znacząco wydłuży to czas pobierania elementu po kluczu. Poniższy rysunek pokazuje sytuację, w której aż 8 par trafiło do pierwszego przedziału.
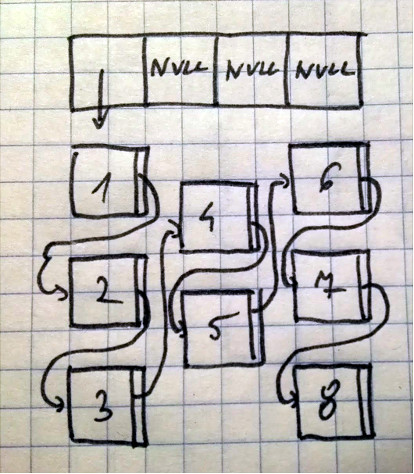
Przy takim rozłożeniu par może wystąpić sytuacja, w której będziemy musieli przejrzeć wszystkie aby znaleźć właściwą.
Dlatego właśnie tablica ta jest automatycznie rozszerzana. Powstaje kolejne pytanie. Kiedy należy taką tablicę powiększyć? Tutaj też wprowadza się pewne wartości domyślne. Możemy powiedzieć o czymś co nazywa się współczynnikiem wypełnienia (ang. load factor). Jeśli nasza tablica jest wypełniona w dość dużym stopniu i liczba elementów przechowywanych w mapie przekroczy pewien próg należy rozszerzyć naszą tablicę.
public class SimpleHashMap<K, V> {
private static final float LOAD_FACTOR = 0.75F;
private static final int INITIAL_CAPACITY = 4;
private int size;
private int threshold;
private List<Entry<K, V>>[] table;
public SimpleHashMap() {
table = new List[INITIAL_CAPACITY];
threshold = (int) (INITIAL_CAPACITY * LOAD_FACTOR);
}
}
Fragment kodu powyżej zakłada, że współczynnik wypełnienia ma wartość 0.75. Zatem próg, po którym tablica przechowująca pary zostanie rozszerzona wynosi 0.75 * 4 == 3. Innymi słowy, jeśli włożymy do mapy 3 pary, to pierwotna tablica o wielkości 4 zostanie powiększona.
Powiększenie tablicy przechowującej pary
Dobrym sposobem na powiększenie wielkości tablicy jest podwojenie jej rozmiaru. Zauważ, że w przypadku powiększenia wielkości tablicy należy od nowa przyporządkować poszczególne klucze do nowych indeksów w tablicy. Funkcja poniżej podwaja wielkość tablicy table i przepisuje pary w odpowiednie miejsca w nowej tablicy:
private void resize() {
if (table.length == Integer.MAX_VALUE) {
return;
}
List<Entry<K, V>>[] oldTable = table;
table = new List[table.length * 2];
threshold = (int) (table.length * LOAD_FACTOR);
for (List<Entry<K, V>> bucket : oldTable) {
if (bucket == null) {
continue;
}
for (Entry<K, V> entry : bucket) {
int hash = hash(entry.key);
if(table[hash] == null) {
table[hash] = new LinkedList<>();
}
List<Entry<K, V>> newBucket = table[hash];
newBucket.add(entry);
}
}
}
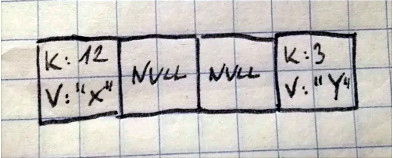
Ilustracja poniżej pokazuje jak po takiej operacji para K: 12, V: "X" znalazła się pod zupełnie innym indeksem. Dzieje się tak ponieważ funkcja hash bierze pod uwagę nową wielkość tablicy. W sytuacji gdy tablica miała rozmiar 4 wówczas 12 % 4 == 0. Po rozszerzeniu ta sama wartość klucza ląduje w innym miejscu w tabeli: 12 % 8 == 4.
Standardowe operacje
Standardowymi operacjami dostępnymi w mapie są:
- dodanie pary klucz, wartość,
- pobranie wartości na podstawie klucze,
- usunięcie pary klucz, wartość,
- sprawdzenie czy dany klucz istnieje,
- pobranie rozmiaru mapy.
Po wprowadzeniu powyżej mogę pokazać Ci przykładową implementację tych operacji.
Dodanie pary do mapy
Dodanie pary do mapy może skutkować utworzeniem nowej pary lub nadpisaniem istniejącej już wartości. Proszę spójrz na przykład poniżej:
public V put(K key, V value) {
int hash = hash(key);
if (table[hash] == null) {
table[hash] = new LinkedList<>();
}
V oldValue = null;
boolean keyExist = false;
List<Entry<K, V>> bucket = table[hash];
for (Entry<K, V> entry : bucket) {
if (keysEqual(key, entry.key)) {
oldValue = entry.value;
entry.value = value;
keyExist = true;
break;
}
}
if (!keyExist) {
bucket.add(new Entry<>(key, value));
size++;
}
if (size == threshold) {
resize();
}
return oldValue;
}
Funkcja ta pobiera wiadro do którego dana para powinna zostać dodana. Następnie iteruje po wszystkich elementach w tym wiadrze, aby sprawdzić czy dany klucz już istnieje. Jeśli klucz istnieje wartość zostaje nadpisana. W przeciwnym wypadku na koniec przedziału zostaje dodana nowa para klucz/wartość.
Teraz widzisz dlaczego porządna funkcja skrótu jest istotna. Jeśli do jednego przedziału trafia dużo elementów to złożoność obliczeniowa takiej operacji wynosi Ο(n). Jeśli natomiast w danym przedziale nie ma innych par klucz wartość wówczas złożoność tej operacji wynosi Ο(1).
Pobieranie wartości z mapy
Pobieranie elementów z mapy sprowadza się do sprawdzenia czy klucz występuje w tablicy. Funkcja skrótu służy do wskazania przedziału, w którym należy szukać instancji klucza. Przykładowa implementacja niżej pozwala na pobranie wartości z mapy:
public V get(K key) {
int hash = hash(key);
List<Entry<K, V>> bucket = table[hash];
if (bucket != null) {
for (Entry<K, V> entry : bucket) {
if (keysEqual(key, entry.key)) {
return entry.value;
}
}
}
return null;
}
Złożoność obliczeniowa wygląda podobnie jak w przypadku dodawania pary do mapy. Jeśli pary są źle rozdystrybuowane, jeśli wszystkie są w jednym przedziale otrzymujemy złożoność Ο(n). Jeśli natomiast w danym przedziale nie ma innych par klucz wartość wówczas złożoność tej operacji wynosi Ο(1).
Usuwanie wartości z mapy
Usuwanie wartości wygląda podobnie do pobierania. W tym przypadku dodatkowo zmniejszana jest wartość atrybutu size przechowującego liczbę par w mapie.
public V remove(K key) {
List<Entry<K, V>> bucket = table[hash(key)];
if (bucket == null) {
return null;
}
Iterator<Entry<K, V>> bucketIterator = bucket.iterator();
V oldValue = null;
while (bucketIterator.hasNext()) {
Entry<K, V> entry = bucketIterator.next();
if (keysEqual(key, entry.key)) {
oldValue = entry.value;
bucketIterator.remove();
size--;
break;
}
}
if (bucket.isEmpty()) {
table[hash(key)] = null;
}
return oldValue;
}
Zwróć uwagę na to, że w przypadku usuwania elementów nie zmniejszam wielkości tablicy z parami – table zostaje bez zmian.
Złożoność obliczeniowa nie różni się od operacji dodawania/pobierania elementów. W zależności od funkcji skrótu i rozłożenia elementów wynosi ona Ο(n) lub Ο(1).
Sprawdzanie rozmiaru mapy
Wszystkie metody modyfikujące zawartość mapy manipulują także atrybutem size. Atrybut ten przechowuje aktualną liczbę elementów.
public boolean isEmpty() {
return size == 0;
}
public int size() {
return size;
}
Kontrakt hashCode i equals
W artykule opisującym porównywanie obiektów opisałem dokładnie kontrakt pomiędzy tymi metodami. Tutaj na przykładzie wyjaśnię Ci dlaczego jest on tak istotny.
Dla przypomnienia, kontrakt ten sprowadza się do trzech reguł:
- Jeśli
X.equals(Y) == truewówczas wymagane jest abyX.hashCode() == Y.hashCode(), - Kilkukrotne wywołanie metody
hashCodena tym samym obiekcie, który nie był modyfikowany pomiędzy wywołaniami musi zwrócić tę samą wartość, - Jeśli
X.hashCode() == Y.hashCode()to nie jest wymagane abyX.equals(Y) == true.
Wyobraź sobie sytuację, w której mamy dwa obiekty. X i Y. Załóżmy, że obiekty te są sobie równe, czyli X.equals(Y) == true. W tej sytuacji metoda hashCode powinna zwrócić tę samą wartość dla obu obiektów. Implementacja jest jednak błędna: X.hashCode() == 4 i Y.hashCode() == 5.
Jeśli użyłbyś obiektów X i Y jako kluczy w mapie wówczas trafiłyby one do różnych przedziałów. Prowadziłoby to złamania założeń mapy. Pamiętaj, że w mapie wszystkie klucze powinny być unikalne. Błędna implementacja hashCode doprowadziłaby do złamania tej reguły.
Jak działa HashMap
Oczywiście HashMap z biblioteki standardowej jest dużo lepszą implementacją niż ta przedstawiona w artykule ;). Poza tym, że jest lepiej przetestowana i posiada dużo więcej przydatnych metod to zawiera także sporo usprawnień, które polepszają jej wydajność.
Dedykowana implementacja kolekcji
Wewnątrz HashMap używa dedykowanej implementacji kolekcji. Nie jest to zwykła lista LinkedList jak w mojej implementacji. Ta kolekcja zmienia swoje właściwości w zależności od liczby elementów znajdujących się w danym przedziale. Standardowo jest to lista wiązana. Jeśli jednak w danym przedziale znajduje się więcej niż 8 elementów wówczas zmienia się w strukturę zwaną drzewem.
Struktura ta pozwala na lepsze wyszukiwanie elementów. Dzięki temu pesymistyczna złożoność obliczeniowa spada z Ο(n) do Ο(log(n)) dla operacji takich jak pobieranie, dodawanie czy usuwanie elementów1.
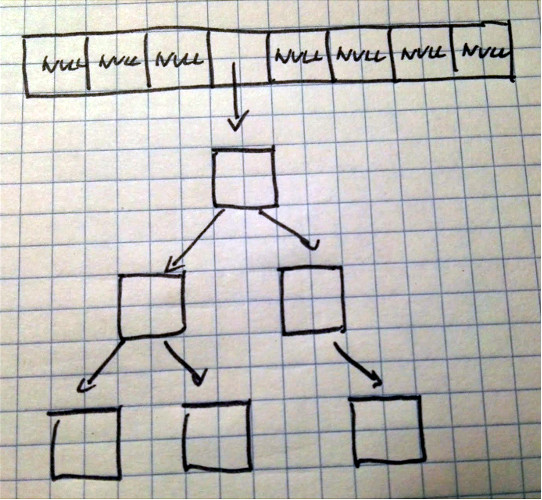
HashMap z drzewem jako kolekcją do przechowywania par
Porównanie złożoności obliczeniowych
Poniższa tabela zawiera zestawienie złożoności obliczeniowych podstawowych operacji dla mapy:
| Operacja | Mapa (dobra funkcja skrótu) | Mapa (zła funkcja skrótu) |
|---|---|---|
| dodawanie pary klucz/wartość | Ο(1) |
Ο(1) |
| usuwanie wartości z klucza | Ο(1) |
Ο(n) lub Ο(log(n)) |
| pobieranie wartości dla klucza | Ο(1) |
Ο(n) lub Ο(log(n)) |
Oczywiście należy brać poprawkę na złożoność obliczeniową dodawania elementów do mapy. Należy pamiętać o tym, że niektóre operacje dodawania kończą się powiększeniem tablicy przechowującej pary. Wówczas złożoność obliczeniowa tej operacji spada do Ο(n).
Najczęściej zadawane pytania
Czy mogę modyfikować klucze
Krótka, zwięzła odpowiedź: nie. Klucze powinny być instancjami klas, które są niemutowalne. Załóżmy, że modyfikacja klucza zmieniłaby wartość zwracaną przez metodę hashCode. Zastanów się, co by się stało gdybyś zmodyfikował instancję klasy, która już jest użyta jako klucz?
Czy pary w mapie są posortowane
Implementacja przedstawiona w tym artykule, czy HashMap nie przechowują elementów w żadnym porządku. Istnieją jednak implementacje, które pozwalają na przykład na przechowywanie elementów w porządku alfabetycznym kluczy (TreeMap) czy według kolejności ich dodawania (LinkedHashMap).
Kiedy używać mapy
Jeśli w programie potrzebujesz przechować strukturę podobną do słownika to mapa jest właśnie tym typem, którego chcesz użyć. Mapy pozwalają na uniknięcie rozbudowanych bloków switch. Użycie ich w taki sposób moim zdaniem poprawia czytelność kodu.
Czy mapa może mieć klucz/wartość null
To zależy od implementacji. Interfejs Map daje taką możliwość. HashMap czy moja implementacja pozwalają przechowywać zarówno klucze i wartości null. Oczywiście tylko jeden klucz może mieć wartość null.
Dodatkowe materiały do nauki
Jeśli chcesz spojrzeć na temat z innego punktu widzenia zachęcam Cię do przeczytania materiałów, które zebrałem poniżej. Szczególnie polecam przejrzenie kodu źródłowego implementacji dostarczonej w SDK:
- Artykuł o tablicy asocjacyjnej na Wikipedii,
- Kod źródłowy przykładów użytych w artykule,
- Implementacja HashMap z OpenJDK.
Zadania do wykonania
Dodaj do Klasy SimpleHashMap kilka metod występujących w interfejsie Map:
- Dodaj metodę
containsKey. Metoda powinna zwrócićtruejeśli dany klucz istnieje w mapie. - Dodaj metodę
containsValue. Metoda powinna zwrócićtruejeśli dany wartość istnieje w mapie. - Jaka jest złożoność obliczeniowa Twojej implementacji metod
containsKeyicontainsValue?
Kod źródłowy klasy SimpleHashMap. Pamiętaj o dodaniu testów jednostkowych, potwierdzających, że Twoja implementacja działa poprawnie.
Podsumowanie
Poznałeś właśnie zasadę działania mapy. Z praktycznej strony poznałeś kontrakt pomiędzy metodami equals i hashCode. Zapoznałeś się z przykładową implementacją mapy. Po rozwiązaniu zadań utrwaliłeś wiedzę z tego zakresu. Powiem Ci w tajemnicy, że o tym jak działa HashMap często pyta się na rozmowach rekrutacyjnych ;). Jesteś zatem o jedno pytanie bliżej otrzymania pracy ;).
Jeśli masz jakiekolwiek pytania czy uwagi proszę daj znać w komentarzu, postaram się pomóc. Jeśli nie chcesz pominąć kolejnych artykułów na blogu proszę dopisz się do samouczkowego newslettera i polub Samouczka na Facebooku. Proszę Cię też o podzielenie się linkiem ze znajomymi, może im także przyda się wiedza zgromadzona w tym artykule.
-
Delikatnie pomijam tu pesymistyczną złożoność obliczeniową dla drzewa. ↩
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.




Zostaw komentarz