To jest wprowadzający artykuł na temat wyrażeń regularnych. Część bardziej zaawansowanych zagadnień związanych z wyrażeniami regularnymi opisana jest w drugiej części:
- zachłanność wyrażeń regularnych,
- alternatywa,
- grupy nieprzechwytujące,
- grupy nazwane,
- ponowne użycie grup,
- kotwice.
Zachęcam do przeczytania drugiej części jeśli chciałbyś dowiedzieć się czegoś więcej o punktach wspomnianych powyżej.
Czym są wyrażenia regularne
Słowo wstępu zanim przejdziemy do teorii. W kilku poniższych akapitach pokażę kilka wyrażeń regularnych bez dokładnego ich omawiania. Posłużą one jako przykłady zastosowania wyrażeń. Proszę nie zrażaj się widząc kilka dziwnych znaczków, później dokładnie je opiszę :).
Wyrażenie regularne (ang. regular expression) to „wzorzec”, który opisuje grupę łańcuchów znaków. Możemy powiedzieć, że łańcuch znaków pasuje do wzorca jeśli dane wyrażenie regularne go opisuje. Na przykład wyrażenie regularne \d{2}-\d{3} opisuje zbiór kodów pocztowych w Polsce. Wyrażenia regularne składają się ze znaków, część z nich w pewnych kontekstach ma specjalne znaczenie. Znaczenie to interpretowane jest przez tak zwany silnik wyrażeń regularnych.
Istnieje wiele silników wyrażeń regularnych, w związku z tym istnieją też pewne różnice pomiędzy wyrażeniami regularnymi rozumianymi przez te silniki. Mówimy wówczas o dialekcie języka wyrażeń regularnych. Dialekty mogą różnić się między sobą pewnymi niuansami, jednak mają wspólną bazę, zrozumiałą dla pozostałych silników wyrażeń regularnych.
Wyrażenia regularne są mechanizmem uniwersalnym, dostępne są w wielu językach programowania. Ucząc się ich raz, poznajesz język wyrażeń regularnych dostępny także w innych językach programowania. Siłą rzeczy skupię się tutaj na dialekcie wyrażeń regularnych w języku Java.
Wyrażenie regularne to tak zwany wzorzec, który następne jest kompilowany przez silnik wyrażeń regularnych do wewnętrznej postaci. Po tym etapie używana jest „wewnętrzna reprezentacja” wyrażenia regularnego. Jeśli spróbujesz skompilować wzorzec, który nie jest poprawny zostaniesz o tym poinformowany odpowiednim wyjątkiem w trakcie działania programu.
Sam etap kompilacji wyrażenia jest procesem relatywnie długim1. Z tego właśnie powodu zaleca się kompilowanie wyrażeń przed ich pierwszym użyciem. Podobnie sprawa ma się jeśli chodzi o tworzenie nowych instancji klasy wzorca. Im ich mniej tym lepiej. Ma to szczególne znaczenie w sytuacji w której używamy wyrażenia wielokrotnie2.
W wyrażeniach regularnych poza „dziwnymi znaczkami” używa się także zwyczajnych liter. Domyślnie w wyrażeniach regularnych wielkość liter ma znaczenie. Wyrażenie regularne Kawa to nie to samo co kawa.
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.
Kiedy używamy wyrażeń regularnych
No właśnie, do czego używamy wyrażeń regularnych? Ogólnie można powiedzieć, że wyrażeń regularnych używamy do pracy z łańcuchami znaków. Wyszukiwanie, dzielenie, czy modyfikacja łańcuchów znaków, to wszystko można zrobić przy pomocy wyrażeń regularnych.
W praktyce jednym z głównych zastosowań jest weryfikacja czy dany łańcuch znaków pasuje do wzorca. Wzorcem tym jest wyrażenie regularne.
To czy łańcuch znaków pasuje do wzorca wykorzystywane jest w trakcie walidacji danych wejściowych. Dzięki wyrażeniom regularnym możemy sprawdzić, czy dane pochodzące od użytkownika mają poprawny format. Na przykład następujące wyrażenie regularne pozwala sprawdzić czy użytkownik podał poprawne imię [A-Z][a-z]+, czy rzeczywiście adres e-mail może być poprawny .+@.+\.pl3, czy format daty, który prowadził użytkownik jest w porządku \d{4}-\d{2}-\d{2}.
Ponadto, wyrażeń regularnych możemy używać do „parsowania” łańcuchów znaków. Jeśli mamy większy łańcuch, z którego chcemy wyciągnąć jakąś część wyrażenia regularne mogą nam w tym pomóc. Na przykład jeśli w telefonie zapisujemy znajomych jako “imię (pseudonim) nazwisko”, wyrażenie regularne \w+ \((\w+)\) \w+ pomoże nam wyciągnąć pseudonim.
Wyrażenia regularne w języku Java
W języku Java wyrażenia regularne obsługiwane są przez dwie klasy z biblioteki standardowej. Są to Pattern i Matcher. Spójrz na przykład poniżej:
Pattern compiledPattern = Pattern.compile("Marcin");
Matcher matcher = compiledPattern.matcher("Nazywam sie Marcin Pietraszek");
System.out.println(matcher.find());
System.out.println(matcher.matches());
W przykładzie tym w pierwszej linijce kompiluję wyrażenie regularne Marcin uzyskując instancję klasy Pattern. W kolejnej linijce wywołując metodę matcher otrzymuję instancję klasy Matcher. Parametr przekazany w metodzie matcher to łańcuch znaków, na którym używamy wyrażenia regularnego.
Klasa Matcher posiada, między innymi, następujące metody:
find()– metoda zwracatruejeśli w łańcuchu znaków znajduje się coś co pasuje do wyrażenia regularnego,matches()– metoda zwracatruejeśli łańcuch znaków pasuje w całości do wyrażenia regularnego.
Proszę spójrz na poniższą tabelkę. W nagłówkach kolumn umieściłem łańcuchy znaków, które dopasowywane są do wyrażeń umieszczonych w pierwszej kolumnie.
| Mam na imię Marcin | Marcinkowski | Marcin | |
|---|---|---|---|
| Marcin | find – truematches – false |
find – truematches – false |
find – truematches – true |
| Marcinkowski | find – falsematches – false |
find – truematches – true |
find – falsematches – false |
Jak widzisz wyrażenia regularne mogą wyglądać jak „normalne” łańcuchy znaków. Jednak takie raczej nie są ciekawe i zbytnio użyteczne. Prawdziwa siła wyrażeń regularnych tkwi w tych wszystkich magicznych znaczkach :). Postaram się je teraz omówić.
Składnia wyrażeń regularnych
Wszystkie przykłady kodu to poprawne testy jednostkowe (więcej o testach przeczytasz w osobnym artykule). Zachęcam do ich skopiowania do IDE i samodzielnego kombinowania :).
Jak już widziałeś w poprzednim przykładzie wyrażenia regularne mogą zawierać zwykłe literały znakowe, na przykład kot czy pies to poprawne wyrażenie regularne. Jednak są znaki, które interpretowane są w specjalny sposób. Wyrażenie takie jak 1 + 2 = 3 zawiera jeden ze znaków specjalnych – znak +. W związku z tym, jeśli znak + chcemy interpretować dosłownie musimy poprzedzić go znakiem \, wówczas pomijamy jego specjalne znaczenie. W takim przypadku otrzymasz wyrażenie regularne 1 \+ 2 = 3.
Wyrażenia regularne a typ String
Jednak to nie koniec „kłopotów”. W języku Java wyrażenia regularne zapisujemy używając typu String. Znak \ jest w literałach znakowych traktowany specjalnie (podobnie jak w samych wyrażeniach regularnych). Na przykład literał znakowy "\t" oznacza znak tabulacji, więc przy zapisie "1 \+ 2 = 3" kompilator Javy doszukiwałby się specjalnego znaczenia dla "\+" (podobnie jak przy "\t") a nie o to nam tutaj chodzi. Dlatego właśnie w języku Java w wyrażeniach regularnych musimy „dublować” każdy ukośnik.
Biorąc pod uwagę powyższe wytłumaczenie nasze wyrażenie regularne, w którym chcemy uciec od specjalnego znaczenia + musimy zapisać jako "1 \\+ 2 = 3.
Mi łatwiej jest to zrozumieć jeśli pomyślę o tym co dzieje się pod spodem:
- pierwszy etap interpretacji literału znakowego (
"1 \\+ 2 = 3") to etap w którym kompilator tworzy reprezentację łańcucha znaków zapisanego w definicji klasy, w trakcie tego etapu ukośniki interpretowane są przez kompilator, - kolejny etap to etap interpretacji łańcucha znaków z definicji klasy (
1 \+ 2 = 3) przez silnik wyrażeń regularnych. W tym etapie silnik wyrażeń regularnych interpretuje łańcuch znaków, który zapisał kompilator.
W naszym przykładzie kompilator interpretując literał znakowy "1 \\+ 2 = 3" w pliku class zawierającym skompilowaną klasę zapisze 1 \+ 2 = 3. Taka postać zostanie zinterpretowana przez silnik wyrażeń regularnych, który zobaczy, że ma pominąć specjalne znaczenie symbolu +.
Pójdźmy o krok dalej. Ten przykład jest już zakręcony więc trzymaj się mocno ;). Co jeśli chcemy sprawdzić numer mieszkania. Załóżmy, że numer mieszkania to kilka cyfr oddzielonych ukośnikiem od kolejnej grupy cyfr. Przykładowy numer pasujący do tego opisu może wyglądać tak 123\5.
Jak już wiesz + dla silnika wyrażeń regularnych jest jednym z symboli specjalnych więc jego użycie trzeba poprzedzać \. W związku z tym sam symbol \ także jest traktowany w specjalny sposób więc i tu jego dosłowne użycie musi być poprzedzone \. Więc w tym przypadku nasze wyrażenie regularne wygląda następująco 123\\5.
A jak takie wyrażenie zapisać jako literał znakowy? Tak, trzeba zdublować każdy ukośnik, więc wychodzi nam taki potworek "123\\\\5".
W dalszej części artykułu jeśli otoczę wyrażenie regularne "" wówczas będzie to poprawny literał (instancja String, z powtórzonymi ukośnikami). Jeśli nie będzie tych znaków, będzie to poprawne wyrażenie regularne (bez powtórzonych ukośników).
Obsługa powtórzeń
W wyrażeniach regularnych istnieje kilka mechanizmów, które pozwalają nam na obsługę powtórzeń, poniżej opiszę wszystkie z nich.
Znak ?
Znak ? oznacza – element znajdujący się wcześniej jest opcjonalny. Innymi słowy to co występuje przed ? może wystąpić raz lub może zostać pominięte. Na przykład do wyrażenia regularnego kr?at pasują zarówno "krat" jak i "kat" ale nie pasuje "kot" czy "krrat".
@Test
public void testSymbolQuestionMark() {
Pattern pattern = Pattern.compile("kr?at");
assertTrue(pattern.matcher("krat").matches());
assertTrue(pattern.matcher("kat").matches());
assertFalse(pattern.matcher("krrat").matches());
assertFalse(pattern.matcher("kot").matches());
}
Znak *
Znak * oznacza – powtórz dowolną liczbę razy element znajdujący się wcześniej. Dowolna liczba to powtórzenie 0 lub więcej razy. Na przykład wyrażenie regularne uwa*ga jest w stanie dopasować następujące łańcuchy znaków "uwga", "uwaga", "uwaaaaaaga" ale nie pasuje do "uwagaaa".
@Test
public void testSymbolAsterix() {
Pattern pattern = Pattern.compile("uwa*ga");
assertTrue(pattern.matcher("uwga").matches());
assertTrue(pattern.matcher("uwaga").matches());
assertTrue(pattern.matcher("uwaaaaaaga").matches());
assertFalse(pattern.matcher("uwagaaaa").matches());
}
Znak +
Znak + jest podobny do *. Oznacza on, że występujący przed nim element musi być powtórzony 1 lub więcej razy. Na przykład wyrażenie regularne trampo+lina może dopasować następujące łańcuchy znaków: "trampolina", "trampooolina" ale nie pasuje do "tramplina".
@Test
public void testSymbolPlus() {
Pattern pattern = Pattern.compile("trampo+lina");
assertTrue(pattern.matcher("trampolina").matches());
assertTrue(pattern.matcher("trampoooolina").matches());
assertFalse(pattern.matcher("tramplina").matches());
}
Powtórzenia inaczej
Poza znakami ?, + i *, które określają dopuszczalną liczbę powtórzeń możesz też użyć {}. Jednak {} ma większe możliwości:
{x}– oznacza że element poprzedzający musi wystąpić dokładnie x razy,{x,}– oznacza, że element poprzedzający musi wystąpić co najmniej x razy,{x,y}– oznacza, że element poprzedzający musi wystąpić od x do y razy.
Zauważ, że symbole ?, * i + możemy zastąpić {}. Na przykład wyrażenia regularne al*a i al{0,}a czy al+a i al{1,}a są sobie równoznaczne. Jednak zapis z ?, + czy * jest krótszy przez co częściej stosowany.
Znak .
Znak oznacza dowolny symbol (poza znakiem nowej linii). Innymi słowy do wyrażenia regularnego ko.ek pasują zarówno "kotek" jak i "korek" ale nie pasuje "koek" czy "ktek".
@Test
public void testSymbolDot() {
Pattern pattern = Pattern.compile("ko.ek");
assertTrue(pattern.matcher("kotek").matches());
assertTrue(pattern.matcher("korek").matches());
assertFalse(pattern.matcher("koek").matches());
assertFalse(pattern.matcher("ktek").matches());
}
Zauważ, że wszystkie dotychczas omówione znaki możemy ze sobą połączyć uzyskując bardziej zaawansowane wyrażenie regularne. Na przykład k+a.*ta. Rozłóżmy to wyrażenie regularne na czynniki pierwsze:
k+– oznacza literę k powtórzoną co najmniej raz,a– litera a,.*– oznacza dowolny znak (poza znakiem nowej linii) powtórzony 0 lub więcej razy,ta– litery ta.
Do takiego wyrażenia regularnego pasują następujące łańcuchy znaków "kata", "katapulta", "karta", "kasia ma kota" czy "kkkka#$*&JHDFStatata ale nie pasuje "ata" czy "kta".
@Test
public void testSymbolDotWithOthers() {
Pattern pattern = Pattern.compile("k+a.*ta");
assertTrue(pattern.matcher("katapulta").matches());
assertTrue(pattern.matcher("karta").matches());
assertTrue(pattern.matcher("kasia ma kota").matches());
assertTrue(pattern.matcher("kkkka#$*&JHDFSta").matches());
assertFalse(pattern.matcher("ata").matches());
assertFalse(pattern.matcher("kta").matches());
}
Teraz już wiesz jak można odczytać wyrażenie regularne użyte na początku artykułu do którego mogą pasować poprawne adresy e-mail .+@.+\.pl. Rozkładając je na czynniki pierwsze mamy:
.+– dowolny symbol użyty co najmniej raz,@– małpka,.+– ponownie dowolny symbol użyty co najmniej raz,\.– kropka rozumiana dosłownie (nie jako specjalny znak wyrażenia regularnego),pl– następujące po sobie litery p i l.
Klasy
W wyrażeniach regularnych też istnieją klasy, jednak nie są to klasy jak w języku Java :). W kontekście wyrażeń regularnych klasy oznaczają grupy symboli, klasy oznaczamy przy pomocy nawiasów [ i ]. Na przykład wyrażenie regularne [rtmp]aca opisuje łańcuchy znaków "raca", "taca", "maca" czy "paca" ale już nie "praca" czy "pacanów".
@Test
public void testSimpleClasses() {
Pattern pattern = Pattern.compile("[rtmp]aca");
assertTrue(pattern.matcher("raca").matches());
assertTrue(pattern.matcher("taca").matches());
assertTrue(pattern.matcher("maca").matches());
assertTrue(pattern.matcher("paca").matches());
assertFalse(pattern.matcher("praca").matches());
assertFalse(pattern.matcher("pacanow").matches());
}
Zakresy znaków
Aby ułatwić zapisywanie grup znaków klasy pozwalają na definiowanie zakresów. Można to zrobić przy pomocy -. Na przykład do wyrażenia regularnego [a-d]uma pasują łańcuchy znaków "auma", "buma", "cuma" czy "duma" ale nie pasuje "fuma" czy "abuma". W podobnym sposób możemy podawać zakresy cyfr. Do wyrażenia regularnego [0-7]xyz pasują łańcuchy znaków "0xyz", "1xyz" czy "7xyz" ale nie pasuje "8xyz" czy "07xyz".
@Test
public void testClassWithRangeNumber() {
Pattern pattern = Pattern.compile("[0-7]xyz");
assertTrue(pattern.matcher("0xyz").matches());
assertTrue(pattern.matcher("1xyz").matches());
assertTrue(pattern.matcher("7xyz").matches());
assertFalse(pattern.matcher("8xyz").matches());
assertFalse(pattern.matcher("07xyz").matches());
}
Jak widzisz znak - wewnątrz klasy ma specjalne znaczenie, jeśli chcesz aby był interpretowany dosłownie umieść go jako ostatni w klasie [abc-].
Zakresy w klasie znaków można ze sobą łączyć. Na przykład do wyrażenia regularnego [a-cA-C0-3]bum pasują łańcucy znaków "abum", "Bbum" czy "0bum" ale nie pasują już "dbum" czy "aA0bum".
@Test
public void testClassWithMultipleRanges() {
Pattern pattern = Pattern.compile("[a-cA-C0-3]bum");
assertTrue(pattern.matcher("abum").matches());
assertTrue(pattern.matcher("Bbum").matches());
assertTrue(pattern.matcher("0bum").matches());
assertFalse(pattern.matcher("dbum").matches());
assertFalse(pattern.matcher("aA0bum").matches());
}
Negacja klasy
A co jeśli chcę dopasować wszystkie znaki prócz x, y i z? Klasy też na to pozwalają. Służy do tego znak ^ umieszczony jako pierwszy w klasie. Na przykład do wyrażenia regularnego [^xyz]awa pasują słowa "kawa", "pawa" czy "Wawa" ale nie pasują "zawa" czy "yawa".
@Test
public void testClassNegation() {
Pattern pattern = Pattern.compile("[^xyz]awa");
assertTrue(pattern.matcher("kawa").matches());
assertTrue(pattern.matcher("pawa").matches());
assertTrue(pattern.matcher("Wawa").matches());
assertFalse(pattern.matcher("zawa").matches());
assertFalse(pattern.matcher("yawa").matches());
}
Jeśli chcesz aby ^ był rozumiany dosłownie wewnątrz klasy nie umieszczaj go na pierwszy miejscu.
Teraz już wiesz jak można odczytać wyrażenie regularne użyte na początku artykułu do którego pasują imiona: [A-Z][a-z]+. Rozłóżmy je na czynniki pierwszej
[A-Z]– znak z tej klasy znaków, wielka litera,[a-z]+– mała litera użyta co najmniej raz.
Predefiniowane klasy znaków
Klasy poznałeś w poprzednich akapitach. Tak się składa, że mechanizm ten jest dość często wykorzystywany w wyrażeniach regularnych. Co więcej, bardzo często zdarzają się klasy, które są częściej używane od innych. Na przykład wszystkie cyfry, czy wszystkie znaki użyte w słowach.
Takie często używane klasy zostały wbudowane w wyrażenia regularne pod postacią predefiniowanych klas. Wszystkie predefiniowane klasy prezentuje lista poniżej:
\d– jakakolwiek cyfra[0-9],\D– jakikolwiek znak, który nie jest cyfrą[^0-9],\w– znak używany w słowach[a-zA-Z0-9_](zauważ, że mamy tu znak_),\W– jakikolwiek znak, który nie jest używany w słowach[^a-zA-Z0-9_],\s– tak zwane białe znaki czyli znak spacji czy tabulacji[ \t\n\r\f\x0B]. Możesz je opisać jako znaki, które nie są widoczne podczas wydruku,\S– negacja grupy\sczyli[^ \t\n\r\f\x0B].
Dla przykładu do wyrażenia regularnego \d\w\d pasują łańcuchy znaków "0_0" czy "0X1" ale nie pasują "a0b" czy "0 0".
@Test
public void testPredefinedClases() {
Pattern pattern = Pattern.compile("\\d\\w\\d");
assertTrue(pattern.matcher("0_0").matches());
assertTrue(pattern.matcher("0X1").matches());
assertFalse(pattern.matcher("a0b").matches());
assertFalse(pattern.matcher("0 0").matches());
}
Pamiętasz o ukośniku? Wyrażenie regularne \d zapisane jako String w języku Java potrzebuje dodatkowego ukośnika, powstaje nam zatem "\\d".
Teraz już wiesz, jak można odczytać wyrażenie regularne użyte na początku artykułu, do którego pasują daty: \d{4}-\d{2}-\d{2}:
\d{4}– cztery cyfry oznaczające rok,-– minus oddzielający rok od miesiąca,\d{2}– dwie cyfry oznaczające miesiąc,-– minus oddzielający miesiąc od dnia,\d{2}– dwie cyfry oznaczające dzień.
Dasz też sobie radę z \d{2}-\d{3} opisującym kody pocztowe.
Grupy
Do tej pory poznałeś mechanizmy wyrażeń regularnych które pozwalają na sprawdzenie czy dany łańcuch pasuje do danego wyrażenia regularnego. Teraz przejdziemy do mechanizmu grup, który pozwala na wyłuskanie z łańcucha znaków pewnego fragmentu wewnątrz.
Weźmy za przykład zdanie "Ala ma kota. Kot ma na imię --Zygmunt--. Kot jest czarny.". Załóżmy, że chcielibyśmy wyciągnąć z tego zdania imię kota. Dla uproszczenia umieściłem je pomiędzy dwoma minusami. Następujące wyrażenie regularne może nam w tym pomóc: [^-]*--(\w+)--.*. Rozłóżmy je na czynniki pierwsze:
[^-]*– Jakikolwiek znak tylko nie minus powtórzony dowolną ilość razy,--– dwa minusy,(– rozpoczęcie grupy,\w+– znak użyty w słowach występujący co najmniej raz,)– zamknięcie grupy,--– dwa minusy,.*– dowolny znak występujący 0 lub więcej razy.
W naszym przykładzie imię Zygmunt znajdujące się pomiędzy podwójnymi minusami zostanie przypisane do grupy. Grupowanie oznaczamy nawiasami (). W wyrażeniu regularnym może być kilka grup, numerowane są one zawsze od jedynki.
Jeśli dany łańcuch znaków pasuje do wyrażenia regularnego wówczas domyślnie ląduje on w grupie z numerem 0.
Obiekt klasy Matcher posiada zestaw metod, które operują na grupach. Skupimy się na dwóch z nich:
groupCount()– zwraca liczbę grup w wyrażeniu regularnym (pomijając tę domyślną z indeksem 0),group(int groupNumber)– zwraca grupę pod konkretnym numerem.
@Test
public void testBasicGroups() {
Pattern pattern = Pattern.compile("[^-]*--(\\w+)--.*");
Matcher matcher = pattern.matcher("Ala ma kota. Kota ma na imie --Zygmunt--. Kot jest czarny.");
matcher.matches();
assertEquals("Zygmunt", matcher.group(1));
}
W przykładzie powyżej widzisz, kod który używa grupowania do pobrania imienia kota ze zdania.
Operatory powtórzeń można stosować do grup. Wyrażenie regularne (\w+ ){3} pasuje do trzech słów, które mogą być oddzielone spacją.
Teraz już wiesz, jak można odczytać wyrażenie regularne użyte na początku artykułu, do odczytywania pseudonimu z książki adresowej \w+ \((\w+)\) \w+. Rozkładając wyrażenie na czynniki pierwsze otrzymujemy:
\w+– cyfry, litery lub podkreślnik użyte co najmniej raz,\(– znak nawiasów użyty dosłownie,(\w+)– ponownie cyfry, litery lub podkreślnik użyte co najmniej raz ale tym razem złapane w grupę,\)– znak nawiasów użyty dosłownie,\w+– po raz kolejny fragment pasujący tym razem do nazwiska.
IDE pomaga
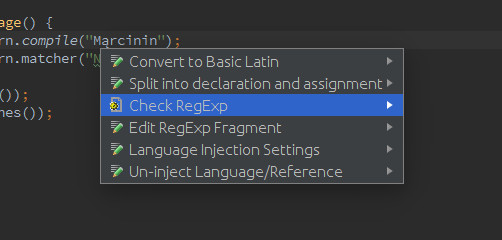
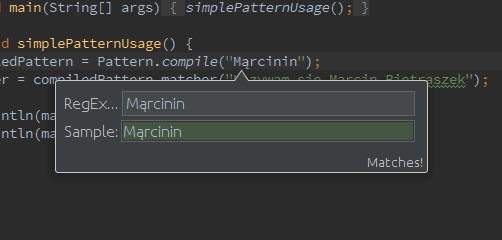
IntelliJ Idea ma dość przydatną funkcję, która pomaga przy pracy z wyrażeniami regularnymi. Naciskając <Alt + Enter> na wyrażeniu regularnym i klikając na „Check RegExp” pokaże się okienko, w którym na żywo możesz sprawdzić działanie wyrażenia regularnego.
Wady wyrażeń regularnych i praktyczne wskazówki
Wyrażenia regularne to bardzo wszechstronne i skomplikowane narzędzie. Narzędzie, które ma dużo możliwości. Jednak niestety ma też swoje wady.
Używanie wyrażeń regularnych gdzie zwykła manipulacja łańcuchami znaków jest możliwa nie zawsze jest dobrym rozwiązaniem. Jeśli można to zrobić prostymi metodami używaj ich zamiast wyrażeń regularnych.
Wyrażenia regularne są wolne. Kompilacja wyrażenia i później ciężka praca silnika wyrażeń regularnych zajmuje więcej czasu niż zwykłe pobranie części łańcucha znaków na przykład od trzeciego do dziesiątego znaku włącznie.
Skomplikowane wyrażenie regularne są ciężkie w utrzymaniu i zrozumieniu. Nadziubać potworka każdy może, gorzej jest później ze zrozumieniem takiego fragmentu miesiąc czy trzy miesiące później. Jeśli to możliwe, lepiej upraszczać je maksymalnie jak się da.
Wyrażenia regularne nie zawsze są w stanie sprawdzić wszystko. Bo jak na przykład napisać wyrażenie regularne, które ze stuprocentową pewnością powie, że data jest poprawna? Podejmujesz się napisania takiego wyrażenia? :) Czy na przykład data 2015-02-29 jest poprawna? Na pierwszy rzut oka wszystko jest z nią w porządku prawda? Napisać wyrażenie regularne, które „udowodni”, że jest ona błędna jest nie lada sztuką, ja bym się chyba takiego zadania nie podjął ;).
Jeśli w Twoim wyrażeniu regularnym jest dużo * zastanów się jeszcze raz czy aby na pewno + nie będzie w tym przypadku wystarczający. Rzadko kiedy zależy nam na „zerowej liczbie znaków”.
Zadania do wykonania
Twoim dzisiejszym zadaniem będzie napisanie kilku wyrażeń regularnych, które będą potrafiły walidować przykładowe dane pochodzące od użytkownika. Napisz wyrażenie regularne, które:
- Sprawdza czy liczba zmiennoprzecinkowa podana przez użytkownika ma poprawny format. Na przykład liczba 123,2341515132135 czy -10 są poprawne ale 18-12 czy 123, już nie,
- sprawdza czy numer domu jest w formacie numer\numer. Poprawnym numerem jest 123\2A, 24B\3 czy 12\5, ale już numer abc\cba nie,
- sprawdza czy użytkownik wprowadził poprawną nazwę miasta. Na przykład Wrocław, Zielona Gora czy Bielsko-Biala jest ok, jednak Ptysiow123 już nie. Dla uproszczenia załóżmy, że żadna nazwa miejscowości nie zawiera polskich znaków.
Rozwiązania jak zwykle są na githubie jednak zachęcam do samodzielnej pracy. Próbując rozwiązać zadania samodzielnie nauczysz się najwięcej.
Dodatkowe materiały do nauki
Poniżej przygotowałem dla Ciebie kilka dodatkowych linków, które zawierają materiały związane z wyrażeniami regularnymi.
- Rubular - narzędzie pozwalające na sprawdzenie wyrażenia regularnego. Co prawda dotyczy wyrażeń regularnych dla języka Ruby jednak w przypadku Javy też znajduje zastosowanie,
- Regexr - kolejne narzędzie pomagające w testowaniu wyrażeń regularnych.
- Regex101 - jak wyżej :),
- http://www.regular-expressions.info - bezsprzecznie najlepszy materiał w sieci jaki znalazłem na temat wyrażeń regularnych. Zawiera szczegółowy opis zarówno tych podstawowych jak i zaawansowanych technik. Sam bardzo często korzystam z tego źródła,
- artykuł na temat wyrażeń regularnych na Wikipedii,
- dokumentacja dla klasy Pattern,
- dokumentacja dla klasy Matcher,
- tutorial dotyczący wyrażeń regularnych na stronie Oracle,
- kod źródłowy przykładów użytych w artykule.
Podsumowanie
Mimo, że artykuł zawiera dość sporą ilość informacji na temat wyrażeń regularnych nie mówi o wszystkich możliwościach. Pominąłem tu celowo na przykład kwestie tak zwanego backtrackingu, zachłanności, alternatyw, nazwanych grup, ponownego użycia grup w wyrażeniu, flag, kotwic itd. Te zagadnienia opisuję w drugiej części.
Tymczasem dzięki za lekturę i na koniec mam do Ciebie prośbę. Proszę podziel się linkiem do artykułu ze swoimi znajomymi, zależy mi na dotarciu do jak największej grupy czytelników i możesz mi w tym pomóc, z góry dziękuję!
-
Mówię to o długim w kontekście innych operacji takich jak dodawanie czy pobranie trzeciej litery z łańcucha znaków. ↩
-
Co prawda w języku Java każda instancja klasy
Patternkompilowana jest dokładnie raz jednak warto zapamiętać tę regułę w przypadku innych języków programowania. ↩ -
Oczywiście to wyrażenie regularne można “oszukać”. Nawet jeśli łańcuch znaków pasuje do wzorca nie musi być poprawnym adresem e-mail. ↩
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.




Zostaw komentarz