Jak wspomniałem wyżej większość zmian związanych było z konfiguracją i integracją poszczególnych komponentów. Zacznę od serwera HTTP.
nginx
Jak wspomniałem w jednym z poprzednich raportów nie chcę rozdmuchiwać kosztów projektu. Nie chciałem też pisać warstwy widoku w oparciu o JSP. Mógłbym statyczne strony HTML zawrzeć w pliku WAR, jednak nie podoba mi się to rozwiązanie.
Moim zdaniem nie jest to podejście, w którym teraz tworzy się nowe strony WWW. Przy jednym pliku WAR miałbym monolityczną aplikację. Przy podejściu, które zastosowałem mam osobną warstwę z interfejsem użytkownika i osobną, która serwuje dane.
Aby obsłużyć taką konfigurację i używać wyłącznie jednej instancji VPS (ang. Virtual Private Server) użyłem serwera nginx.
Na tej samej instancji uruchomiony jest serwer Tomcat. W związku z konfiguracją firewall’a na tej maszynie nie jest on jednak dostępny bezpośrednio. nginx skonfigurowałem jako “reverse proxy”. Sprowadza się to do tego, że część żądań przesyłana jest przez nginx to Tomcata. Pozostała część to serwowanie statycznych stron.
W uproszczeniu konfiguracja ta podobna jest do tej pokazanej na diagramie poniżej:
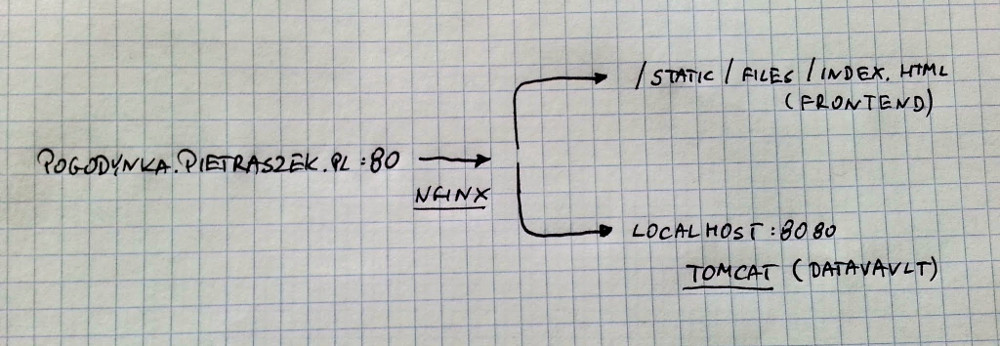
Interfejs użytkownika wykorzystywał będzie aplikację webową do pobrania informacji o dotychczasowych odczytach temperatury.
PostgreSQL
Baza danych, którą skonfigurowałem do pracy z projektem nie nadaje się na produkcję. Mowa tu o HyperSQL. Do produkcyjnego działania potrzebna jest baza z prawdziwego zdarzenia. I tak pojawił się PosgreSQL.
Przy pomocy puppet’a skonfigurowałem serwer bazy danych, utworzyłem bazę i dodałem odpowiednich użytkowników. Użytkownik, którego używam w aplikacji ma uprawnienia tylko do części elementów. Konfigurację możesz zobaczyć na githubie.
Dodatkowo sama baza danych zainstalowana jest na tym samym VPS co Tomcat. Dzięki temu nie ma potrzeby “otwierać” bazy danych na świat. Dostępna jest ona wyłącznie lokalnie. Zapewnia to sama konfiguracja PostgreSQL oraz reguł firewall’a.
Raspberry PI
Stwierdziłem, że skoro mam już Puppeta to wykorzystam go także po stronie Raspberry PI. Podzieliłem manifesty w ten sposób, że konfiguracja Malinki także jest jasno opisana. Całość znajduje się w pliku node_thermometer.pp.
Dzięki takiemu podejściu mam spójny sposób na konfigurację wszystkich “serwerów” jakie używam. Dodatkowo nie muszę już manualnie zarządzać wpisami w crontab. Robi to za mnie puppet.
Konfiguracja serwera Tomcat
Aplikacje Datavault i Thermometer starałem się pisać w taki sposób aby móc udostępnić kod publicznie.
Ma to pewne konsekwencje. Mianowicie pewne elementy takie jak hasła nie powinny być publicznie dostępne. Aby to obejść użyłem zmiennych środowiskowych. Używam takiej zmiennej na przykład aby pobrać hasło użytkownika bazy danych.
Zmienne te są ustawione na serwerze za pomocą puppet’a. Ich wartość pobierana jest za pośrednictwem mechanizmu hiera (opisałem go w jednym z poprzednich artykułów opisujących projekt Pogodynka) więc nie są to dane dostępne publicznie.
Zmiany w kodzie
Jak wspomniałem zmian w kodzie Javy było niewiele. Można je podzielić na dwie części:
- wspólne interfejsy,
- uwierzytelnianie.
Wspólne interfejsy
Pogodynka składa się z trzech modułów: Datavault, Thermometer i Frontend. Thermometer wysyła dane do Datavault używając zapytania HTTP. Zapytanie to zawiera dane w formacie JSON.
W aplikacji Thermometer wysyłałem dane sformatowane w trochę inny sposób niż było to oczekiwane przez Datavault. Jako konsekwencja Datavault zwracał odpowiedzi ze statusem 400 na każde żądanie wysłane z Thermometer. Uwspólnienie formatu rozwiązało problem.
Uwierzytelnianie
Chociaż dane z termometru są publicznie dostępne to powinny być dostępne wyłącznie do odczytu. Możesz to sprawdzić otwierając stronę pogodynki.
Zależy mi na tym aby te dane były rzetelne. Sprowadza się to do tego, że tylko określeni użytkownicy powinni móc dodawać informacje o aktualnych odczytach.
Nie chciałem zbytnio komplikować mechanizmu uwierzytelniania/autoryzacji więc poszedłem po najmniejszej linii oporu. Mianowicie przy żądaniu wysyłającym nowy pomiar sprawdzana jest zawartość pewnego nagłówka. Jeśli zawartość ta jest błędna żadne dane nie są dodawane do bazy. W odpowiedzi wysyłany jest kod 403.
Ta tajna wartość nagłówka również przechowywana jest w zmiennej środowiskowej.
Brakujące elementy
Czujnik zewnętrzny
Aktualnie całość działa w oparciu o czujnik wewnętrzny. Takie podejście raczej nie przejdzie próby deszczu ;). Kupiłem czujnik zewnętrzny, Mam nadzieję, że jutro już będzie uruchomiony.

Interfejs użytkownika
Chociaż szablon interfejsu użytkownika jest już dostępny, nie jest on prawidłowy. Aby miał on sens musi pobierać dane o temperaturach z Datavault. Właśnie na tej części skupię się w przeciągu najbliższych dni.
Podsumowanie
Integrację mogę uznać za ukończoną. Monitoring całości opisany w początkowych odcinkach także działa. Zostały ostatnie szlify. Myślę, że mam duże szanse ukończyć projekt w terminie. Konkurs “Daj się poznać” trwa do 31.05.2017 więc zostało jeszcze parę dni. Trzymajcie kciuki i do następnego razu!
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.




Zostaw komentarz