Ten artykuł pokazuje kolejną odsłonę projektu Pogodynka. Jeśli jesteś zainteresowany starszą wersją odsyłam Cię do serii poprzednich artykułów:
- Projekt Pogodynka – wprowadzenie
- Projekt Pogodynka – naiwny termometr
- Projekt Pogodynka – działający termometr
- Projekt Pogodynka – szkielet aplikacji webowej
- Projekt Pogodynka – JSON i walidacja
- Projekt Pogodynka – JPA i Spring Data
- Projekt Pogodynka – konfiguracja serwera
- Projekt Pogodynka – konfiguracja bazy danych
- Projekt Pogodynka – szkic interfejsu użytkownika
- Projekt Pogodynka – integracja
- Projekt Pogodynka – podsumowanie
Nowe podejście
Hardware
Starsza wersja pogodynki zawierała więcej komponentów, nad którymi pracowałem samodzielnie. Wówczas postawiłem na serwer współdzielony, na którym zainstalowałem niezbędne elementy takie jak silnik bazy danych czy serwer HTTP. Stary diagram wygląda tak:
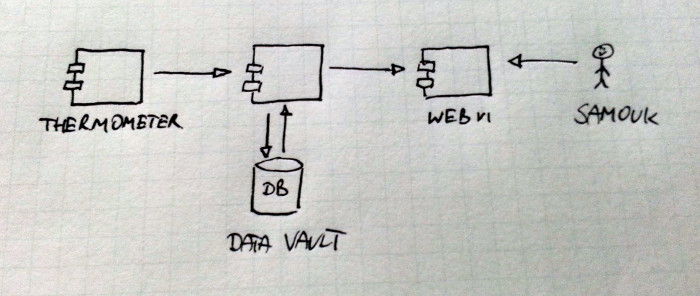
Takie podejście ma swoje wady i zalety. Niestety w skali tak małego projektu doświadczałem głównie wad:
- byłem odpowiedzialny za utrzymanie wszystkich komponentów,
- koszt serwera był relatywnie wysoki,
- zdarzały się przerwy w dostępności Pogodynki.
Biorąc te elementy pod uwagę postanowiłem zmienić podejście. Tym razem jedynym sprzętem za który jestem odpowiedzialny jest Rasberry Pi z zestawem czujników. Reszta to płatne usługi. Mimo tego, że usługi te są płatne, finalnie koszt będzie dużo niższy. Dokładny opis szacowania kosztów znajdziesz w jednym z punktów poniżej.
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.
Software
Kolejnym elementem, który zmieniłem jest stos technologiczny. Stara wersja Pogodynki używała głównie języka Java. Do tego przygotowałem prosty interfejs użytkownika przy pomocy HTML, CSS i JavaScript. Do zarządzania infrastrukturą użyłem Puppet’a.
Nowe podejście jest mocno uproszczone. Użyłem języka Python. Do zarządzania zasobami w chmurze posłużyłem się Terraform’em.
Nowa pogodynka
Czujnik pyłu zawieszonego SDS011
Przebudowując Pogodynkę rozszerzyłem ją o dodatkowy czujnik. Teraz Pogodynka może także mierzyć ilość pyłu zawieszonego o średnicy 2.5μm i 10μm. Podstawowa wersja kodu, którą napisałem sprawia, że czujnik działa bez przerwy. Pogodynka 2.1 mogłaby włączać czujnik na żądanie wydłużając żywotność lasera.
Python vs Java
Co tu dużo mówić, większą frajdę sprawia mi pisanie kodu w Python’ie. Między innymi z tego powodu zdecydowałem, że Pogodynka 2.0 używa tego języka programowania. Proszę spójrz na przykład poniżej:
class SDS011:
DATA_PACKET_SIZE = 10
HEADER = 0xAA
TAIL = 0xAB
def __init__(self, port):
self.port = port
def poke_25(self):
data = self.read_bytes()
return int.from_bytes(data[2:4], byteorder="little") / 10
def poke_10(self):
data = self.read_bytes()
return int.from_bytes(data[4:6], byteorder="little") / 10
def read_bytes(self):
data = self.port.read(self.DATA_PACKET_SIZE)
assert data[0] == self.HEADER
assert data[9] == self.TAIL
return data
Te 24 linijek kodu to wszystko, co jest potrzebne do obsługi czujnika SDS011 (dla czytelności pominąłem dokumentację i komentarze). Aż boję się pomyśleć ile musiałbym się nadziubać, żeby zaimplementować to w Javie :). Testy jednostkowe dla kodu są równie zwięzłe:
@pytest.fixture
def port_mock():
port_mock = mock.MagicMock()
port_mock.read.return_value = b"\xaa\xc0\x1c\x001\x00\x0b\x141\xab"
return port_mock
def test_pm25(port_mock):
pm_sensor = sds011.SDS011(port_mock)
assert pm_sensor.poke_25() == pytest.approx(2.8)
def test_pm10(port_mock):
pm_sensor = sds011.SDS011(port_mock)
assert pm_sensor.poke_10() == pytest.approx(4.9)
Google Cloud Platform
Przeniosłem Pogodynkę do chmury :). Postawiłem na Google BigQuery jako bazę danych, w której przechowuję wyniki pomiarów. Przesiadka na BigQuery pozwoliła mi zwiększyć częstotliwość pomiarów bez przejmowania się potencjalnymi problemami z wydajnością bazy danych. Pogodynka 2.0 wysyła wskazania czujników co minutę.
Za strumieniowe przesyłanie danych do chmury odpowiedzialny jest poniższy fragment kodu:
def stream_to_gbq(client, scoped_table, measurements):
rows_to_insert = []
for measurement in measurements:
row = {
"time": measurement.time.strftime(GBQ_TIMESTAMP_FORMAT),
"pm25": measurement.pm25,
"pm10": measurement.pm10,
"temperature": measurement.temperature,
}
rows_to_insert.append(row)
try:
errors = client.insert_rows_json(scoped_table, rows_to_insert)
except exceptions.BadRequest as e:
raise StoreError(e)
if errors != []:
raise StoreError(errors)
Zrezygnowałem też z własnego narzędzia do wizualizacji na rzecz Google DataStudio. Przykładowy raport wygenerowany na podstawie danych zebranych przez Pogodynkę 2.0 możesz zobaczyć poniżej:
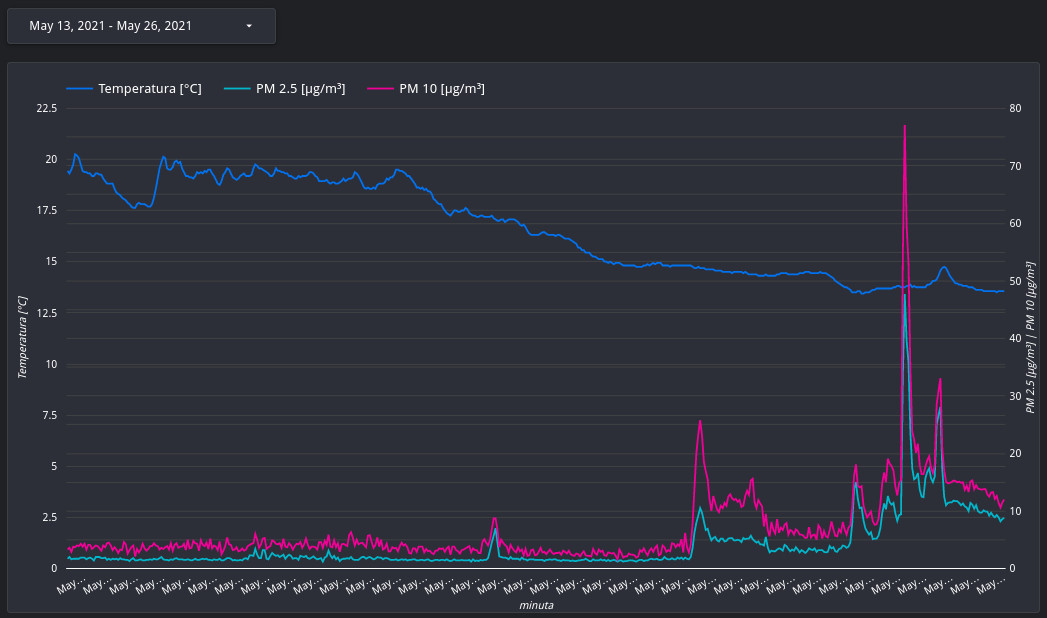
Starałem się maksymalnie ograniczyć liczbę komponentów żeby niepotrzebnie nie komplikować rozwiązania.
Terraform
W związku z przesiadką na chmurę odstawiłem w kąt Puppet’a. Tym razem użyłem Terraform’a do zarządzania wszystkimi zasobami w chmurze. Przechowywanie definicji infrastruktury jako kod ma wiele zalet. Jedną z nich jest możliwość wglądu w historię zmian. Konfiguracja w przypadku Pogodynki 2.0 nie jest skomplikowana. Możesz ją przejrzeć w publicznym repozytorium.
Funkcja cache
Przy Pogodynce 1.0 zauważyłem, że elementem, który był najbardziej zawodny był dostęp do internetu w miejscu gdzie działała Pogodynka. Skutkowało to utratą wyników pomiarów wykonanych w czasie, kiedy nie było dostępu do internetu.
Tym razem postanowiłem to zmienić wprowadzając lokalny cache. W przypadku braku dostępu do internetu Pogodynka 2.0 zapisuje wyniki pomiarów lokalnie. Raz jeszcze dzięki Python’owi cały kod jest niesłychanie zwięzły:
class Cache:
def __init__(self, cache_path):
self.cache_path = cache_path
def load(self):
if not path.isfile(self.cache_path):
return []
with open(self.cache_path, "rb") as cache_file:
return pickle.load(cache_file)
def dump(self, measurements):
with open(self.cache_path, "wb") as cache_file:
pickle.dump(measurements, cache_file)
def clear(self):
self.dump([])
Połączenie klas wspomnianych wyżej możesz zobaczyć poniżej:
pm_port = serial.Serial(args.pm_sensor_device)
pm_sensor = sds011.SDS011(pm_port)
temperature_sensor = ds18b20.DS18B20(args.temperature_sensor_path)
cache = store.Cache(args.cache_path)
measurements = cache.load()
measurements.append(
sensor.Measurement(
time=datetime.datetime.utcnow(),
pm25=pm_sensor.poke_25(),
pm10=pm_sensor.poke_10(),
temperature=temperature_sensor.poke(),
),
)
gbq_client = bigquery.Client()
try:
store.stream_to_gbq(gbq_client, args.destination_table, measurements)
cache.clear()
except store.StoreError:
cache.dump(measurements)
raise
Na początku tworzę instancje klas obsługujących czujniki. Kolejna linijka to utworzenie instancji klasy obsługującej lokalny cache. Następne linijki to utworzenie listy pomiarów do wysłania.
W końcu wysyłam pomiary do tabeli w Google BigQuery.
Przygotowanie karty SD
System, które używałem w przypadku Pogodynki 1.0 ma już swoje lata. Zdecydowałem się zaktualizować go do najnowszej wersji. Ze strony Rasberry Pi pobrałem najnowszą wersję systemu Raspberry Pi OS Lite. Obraz skopiowałem na kartę microSD zgodnie z instrukcją ze strony Raspberry Pi.
Po uruchomieniu malinki zaktualizowałem zainstalowane oprogramowanie i dodałem kilka dodatkowych narzędzi:
apt-get update
apt-get upgrade
apt-get install python3-pip python3-venv git vim tree
Kod odpowiedzialny za Pogodynkę uruchamiany jest w kontekście dedykowanego użytkownika:
useradd pogodynka
usermod --append --groups dialout pogodynka
Ostatnia komenda dodaje użytkownika pogodynka do grupy dialout. Jest to potrzebne, aby mieć bezpośredni dostęp do odczytu danych z portu USB.
Wszystkie te operacje wykonałem podłączając klawiaturę bezpośrednio do malinki. Dla wygody włączyłem demona ssh, dzięki czemu pozostałe operacje mogę wykonać zdalnie:
touch /boot/ssh
Moduły jądra Linux’a
Żeby termometr działał poprawnie wymagana jest drobna modyfikacja konfiguracji malinki:
echo dtoverlay=w1-gpio >> /boot/config.txt
reboot
modprobe w1-gpio
modprobe w1-therm
Stara architektura a chmura
Porównanie kosztów
Pogodynka 1.0 używała serwera współdzielonego. Korzystałem z usług jednej z polskich firm hostingowych. Koszt utrzymania serwera wynosił około 10zł miesięcznie. Pogodynka 2.0 to zupełnie inna para kaloszy. Szacowanie kosztów usług chmurowych jest dużo bardziej złożone. W przypadku usług, z których korzystam składniki ceny są następujące:
- przechowywanie danych w bazie danych – kosztuje $0,02 za 1GB przechowywanych danych1,
- strumieniowe ładowanie danych do bazy – kosztuje $0,01 za 200MB, ładowany wiersz to minimum 1KB,
- pobieranie danych z bazy danych – kosztuje $5 za każdy odczytany 1TB.
Koszt przechowywania danych
Spróbuję oszacować wielkość bazy danych po roku:
60 (odczytów na godzinę) * 24 (godziny) * 365 (dni) = 525'600 (odczytów rocznie)
Każdy odczyt to jeden wiersz. Tabela przechowująca pomiary składa się z czterech kolumn:
- daty typu
DATETIME - odczytu temperatury typu
FLOAT - odczytu PM2.5 typu
FLOAT - odczytu PM10 typu
FLOAT
Każda z tych kolumn to 8B, więc jeden wiersz to 8B * 4 = 32B. Zatem 525’600 odczytów rocznie to w sumie 17MB (16’819’200B). Zatem przechowywanie całego roku danych kosztuje aż $0,00034. A… zapomniałem dodać, że pierwsze 10GB jest darmowe. Innymi słowy przy takiej skali danych nie muszę się przejmować opłatami za przechowywanie danych.
Koszt ładowania danych
Zdecydowałem się na ładowanie strumieniowe żeby mieć natychmiastowy dostęp do danych. Strumieniowe ładowanie danych jest płatne. W ciągu miesiąca Pogodynka 2.0 doda do bazy następującą liczbę wierszy:
60 (odczytów na godzinę) * 24 (godziny) * 30 (dni) = 43'200 (odczytów miesięcznie)
Żądanie dodania danych do bazy ma minimum 1KB (w przypadku Pogodynki 2.0 jest dużo mniejsze, jednak takie jest ograniczenie narzucone przez Google BigQuery). Zatem w ciągu miesiąca strumieniowo zostanie przesłanych 43,2MB danych. Podsumowując, miesięczny koszt strumieniowego ładowania danych to $0,0002. Myślę, że mogę żyć z takim zobowiązaniem ;).
Koszt pobierania danych z bazy
Nie planuję odczytywać danych samodzielnie. Dane będą odczytywane przez raport, który utworzyłem w DataStudio. Dla uproszczenia pomijam tu kwestię przechowania wyników w cache’u, która obniży finalny koszt.
Załóżmy, że pogodynka będzie działała przez 1000 lat ;). W trakcie tak długiego czasu w bazie uzbiera się 17GB. Jednorazowy odczyt tysiącletniej historii pomiarów czujników Pogodynki 2.0 kosztowałby $0,09. A… znów zapomniałem o tym, że pierwszy 1TB w miesiącu jest darmowy. Po raz kolejny przy takiej skali danych nie muszę się przejmować opłatami za odczyt danych z bazy.
Finalne porównanie
W tym konkretnym przypadku chmura jest praktycznie darmowa. Pamiętaj jednak, że podobną analizę kosztów warto zrobić dla konkretnego przypadku – koszty rozwiązań chmurowych potrafią zaskoczyć, jeśli projektowane rozwiązania nie są efektywne.
Dla przykładu, w pierwotnej wersji Pogodynki 2.0 każdy czujnik zapisywał pomiar w osobnym wierszu. Sprowadzał się do do trzy razy większej liczby wierszy – trzy razy wyższym koszcie za strumieniowe przesyłanie danych. W skali Pogodynki $0,0002 czy $0,0006 nie robi większej różnicy, jednak w produkcyjnych systemach operujących na dużych zbiorach danych takie szczegóły mogą być bardzo istotne.
Infrastruktura jako kod
Pracując z projektami opartymi o chmurę miałem do czynienia z różnym podejściem do zarządzania zasobami w chmurze. W części z projektów zasoby były tworzone ręcznie. Całość konfiguracji odbywała się ręcznie przez interfejs dostarczony przez dostawcę chmury.
Na dłuższą metę takie podejście jest uciążliwe. Używanie narzędzi pokroju Terraform znacząco ułatwia pracę w projekcie opartym o chmurę.
Podsumowanie
Pogodynka 2.0 już działa. Zachęcam Cię do samodzielnego wykonania takiego projektu. Koszt jaki będziesz musiał ponieść jest znikomy w porównaniu do wiedzy, którą możesz zdobyć. Jedynym znaczącym kosztem jest cena samej malinki (aktualnie około 180zł) i czujnika SDS011 (aktualnie około 70zł).
Kod źródłowy Pogodynki 2.0 dostępny jest na Samouczkowym Githubie.
Mam nadzieję, że artykuł był dla Ciebie pomocny. Proszę podziel się nim ze swoimi znajomymi. Dzięki temu pozwolisz mi dotrzeć do nowych Czytelników, za co z góry dziękuję. Jeśli nie chcesz pominąć kolejnych artykułów dopisz się do samouczkowego newslettera i polub Samouczka Programisty na Facebooku.
Do następnego razu!
-
Dla uproszczenia obliczeń pomijam tutaj tak zwane „long-term storage”, dane starsze niż 90 dni kosztują $0,01 za 1GB ↩
Pobierz opracowania zadań z rozmów kwalifikacyjnych
Przygotowałem rozwiązania kilku zadań algorytmicznych z rozmów kwalifikacyjnych. Rozkładam je na czynniki pierwsze i pokazuję różne sposoby ich rozwiązania. Dołącz do grupy ponad 6147 Samouków, którzy jako pierwsi dowiadują się o nowych treściach na blogu, a prześlę je na Twój e-mail.




Zostaw komentarz